Learn to process long texts using Sentence Transformer, an AI tool, on a PC. Evaluate with JupyterLab and improve document searches, efficiency, and inquiry matching.

相模原市で IoT 設計を受託しているファームロジックスです。
先日のブログでは、無償で公開されている Sentence Transformer という機械学習(ML)、すなわち AI のツールを使って、さまざまなテキストの類似度を求める、という技術を紹介しました。
そのような AI 技術を使うことで、企業で大量に抱えるドキュメント(文章ファイル)の中から、別のドキュメントに類似しているものを探し出す、ということが自動的にできるようになります。さらにこの技術を応用することで、曖昧なキーワードを使って社内ドキュメントを検索したり、お客様からの問い合わせにもっとも適合する自社製品の仕様書を見つけたり、といったことも可能になります。
前回に残した問題
しかし、前回のブログで書いたように、紹介した方法には一つ問題がありました。それは、紹介した Sentence Transformer モデル paraphrase-multilingual-MiniLM-L12-v2 では、デフォルトで 128トークンより長いテキストを処理することができない、というものです。
今回はこの問題への対応策を考えてみたいと思います。検討作業にあたっては、JupyterLab というツールを使いました。今回は、その JupyterLab で作成したノートを紹介するという形で進めていきます。
問題の詳細
前回、SBERT.net の Sentence Transformer を使うことで、以下のようなコードによりテキストの特徴量ベクトル(embedding)を得ることができることを説明しました。
sentences = [
"The weather is lovely today.",
"It's so sunny outside!",
"He drove to the stadium.",
]
embeddings = model.encode(sentences)
しかし、ここで次のような問題があります。Sentence Transformer のモデルには一度に処理できるトークンの数に制限があることです。(モデルによってトークン数の制限は異なります。)
“The weather is lovely today.” のような短いテキストであれば Sentence Transformer のモデルは一度に特徴量ベクトルを求めることができますが、長いテキストは処理できないことが多いのです。
max_seq_length と max_position_embeddings について
Computing Embeddings — Sentence Transformers documentation で説明されています。(以下、日本語要約)
BERT、RoBERTa、DistilBERT などのトランスフォーマーモデルでは、入力長が増加するにつれて、実行時間とメモリの必要量が入力長に対して二次的に増加します。このため、トランスフォーマーモデルは特定の長さまでの入力に制限されます。BERTベースのモデルの場合、一般的な値は512トークンで、これは英語では約300~400単語に相当します。
各モデルには
model.max_seq_lengthという最大シーケンス長が設定されており、処理可能なトークン数の上限が定義されています。より長いテキストは、このmodel.max_seq_lengthトークン数の範囲内に収まるよう、最初の部分に切り詰められます。
もう少し調べてみたところ、次のことが分かりました。
Sentence Transformer モデルの max_seq_length は、モデルの使用するトークナイザが一度に処理するトークン数であり、Hugging Face モデル定義の sentence_bert_config.json(一例)に記述されています。 デフォルトで 128 や 256 などの小さな値に設定されており、長いテキストをモデルに渡すとその設定を超える部分は切り捨てられます。
しかし max_seq_length は、モデルを使用してトークンを分割する時のデフォルト設定であり、モデル自体は config.json (一例)で設定された別のパラメタ max_position_embeddings(512 など)個のトークンまで処理できるように実装(事前トレーニング)されています。 必要であれば、max_seq_length は最大 max_position_embeddings までの値に設定することができます。 (ただし、変更する際には、計算コストやメモリ使用量の増加に注意しましょう。)
- 参考 1: Computing Embeddings — Sentence Transformers documentation
- 参考 2: Creating Custom Models — Sentence Transformers documentation
トークナイザの概要
Sentence Transformer に代表されるトランスフォーマーがテキストを処理する際には、あらかじめテキストのトークン化、その他の前処理が必要となります。 テキストのトークン化をするのがトークナイザです。 Hugging Face で公開されているトランスフォーマーのモデルには、モデルの事前学習時に使用されたボキャブラリやルールに基づいて動作する、最適化されたトークナイザの実装が付随しています。
今回は、事前トレーニング済みの Sentence Transformer モデルである paraphrase-multilingual-MiniLM-L12-v2 を使って話を進めることにします。 Sentence Transformer に含まれているトークナイザのインスタンスを取り出すには、以下のようにして実行できます。実際にやってみましょう。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2")
tokenizer = model.tokenizer
print(type(tokenizer))
結果:
<class 'transformers.models.bert.tokenization_bert_fast.BertTokenizerFast'>
参考までに、上で表示された BertTokenizerFast とは、オリジナルの Python 実装である BertTokenizer の高速版であり、処理速度が高く、大規模なデータセットのトークン化にも適しています。
あるいは次のようにしても取得できます。
from transformers import AutoTokenizer
tokenizer2 = AutoTokenizer.from_pretrained(
"sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
)
print(type(tokenizer2))
結果:
<class 'transformers.models.bert.tokenization_bert_fast.BertTokenizerFast'>
AutoTokenizer で明示的に Transformer を取得する際には、sentence-transformers/ というプレフィックスが必要となります。
なお、上で得られる tokenizer と tokenizer2 では、.model_max_length などの属性値が異なる場合があるので注意が必要です。(詳細は略)
print("tokenizer:", tokenizer.model_max_length)
print("tokenizer2:", tokenizer2.model_max_length)
結果:
tokenizer: 128 tokenizer2: 512
長いテキストをトークン化してみる
次に、例として、前回のノートブックで試した「ブログ記事」のテキストを再度取り上げます。次のようなテキストでした。
皆様は既に、OpenAI 社の ChatGPT を日頃の業務に活用なさっていることと思います。ChatGPT は非常に優れたサービスですが、当然ながら、OpenAI 社が開発した大規模言語モデル(LLM)しか使用できません。GPT-4o や o1-preview といったモデルは、高度な応答が得られる反面、基本的に有償で利用する必要があります。ところで、HuggingChat というサービスをご存知でしょうか。HuggingChat は、様々な開発元による多数の言語モデルを自由に切り替えて使用できる、非常に興味深いプラットフォームです。このサービスは驚くべきことに無償で提供されており、異なるモデルを手軽に試すことができるのが特徴です。ユーザーは、各モデルの応答の違いや特性を比較しながら、自分の目的に最適な言語モデルを選ぶことができます。今回は、この HuggingChat を使って、
これをトークナイザ(BertTokenizerFast)で処理し、どのようなことをしているのか覗いてみましょう。 (これから何度か参照するので、このテキストを定数 ORIG_SENTENCE に代入しておきます。)
ORIG_SENTENCE = "皆様は既に、OpenAI 社の ChatGPT を日頃の業務に活用なさっていることと思います。ChatGPT は非常に優れたサービスですが、当然ながら、OpenAI 社が開発した大規模言語モデル(LLM)しか使用できません。GPT-4o や o1-preview といったモデルは、高度な応答が得られる反面、基本的に有償で利用する必要があります。ところで、HuggingChat というサービスをご存知でしょうか。HuggingChat は、様々な開発元による多数の言語モデルを自由に切り替えて使用できる、非常に興味深いプラットフォームです。このサービスは驚くべきことに無償で提供されており、異なるモデルを手軽に試すことができるのが特徴です。ユーザーは、各モデルの応答の違いや特性を比較しながら、自分の目的に最適な言語モデルを選ぶことができます。今回は、この HuggingChat を使って、"
sentence = ORIG_SENTENCE
tokens = tokenizer(sentence)
print("トークン化結果:", tokens)
print("トークンの数:", len(tokens["input_ids"]))
print("トークン:", tokenizer.convert_ids_to_tokens(tokens["input_ids"]))
結果:
Token indices sequence length is longer than the specified maximum sequence length for this model (188 > 128). Running this sequence through the model will result in indexing errors
トークン化結果: {'input_ids': [0, 6, 90746, 342, 142793, 37, 103264, 11388, 6, 6808, 154, 18032, 724, 22693, 6, 251, 635, 34362, 154, 24712, 327, 67035, 1308, 6437, 12087, 8184, 9700, 30, 171126, 724, 22693, 6, 190313, 227635, 20610, 8989, 37, 14139, 17114, 37, 103264, 11388, 6, 6808, 281, 47479, 2419, 179821, 148654, 91191, 132, 23708, 594, 16, 23731, 2229, 67524, 30, 724, 22693, 11565, 31, 6, 1217, 36, 20268, 254, 132340, 6, 53494, 91191, 342, 37, 34569, 1308, 63346, 24450, 281, 1844, 14446, 7606, 2879, 37, 102004, 465, 140570, 507, 5410, 187021, 30, 98179, 37, 30513, 36659, 171126, 6, 2573, 123248, 194807, 40438, 30, 30513, 36659, 171126, 6, 342, 37, 33903, 47479, 2954, 31214, 68854, 154, 148654, 91191, 251, 178442, 233001, 3014, 2229, 9885, 37, 4528, 165981, 164764, 133628, 14670, 125050, 1453, 30, 3619, 20610, 342, 23881, 2928, 84193, 45810, 2705, 140570, 507, 2212, 143689, 37, 120253, 91191, 251, 238862, 12324, 7056, 61084, 12161, 109399, 1453, 30, 57064, 342, 37, 4035, 91191, 154, 63346, 24450, 163750, 1217, 59384, 251, 9455, 58030, 37, 11748, 16205, 327, 207535, 148654, 91191, 126290, 47420, 30, 58839, 37, 3619, 7674, 36659, 171126, 6, 44312, 37, 2], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
トークンの数: 188
トークン: ['<s>', '▁', '皆様', 'は', '既に', '、', 'Open', 'AI', '▁', '社', 'の', '▁Chat', 'G', 'PT', '▁', 'を', '日', '頃', 'の', '業務', 'に', '活用', 'な', 'さ', 'っている', 'こと', 'と思います', '。', 'Chat', 'G', 'PT', '▁', 'は非常に', '優れた', 'サービス', 'ですが', '、', '当然', 'ながら', '、', 'Open', 'AI', '▁', '社', 'が', '開発', 'した', '大規模', '言語', 'モデル', '(', 'LL', 'M', ')', 'しか', '使用', 'できません', '。', 'G', 'PT', '-4', 'o', '▁', 'や', '▁o', '1-', 'p', 'review', '▁', 'といった', 'モデル', 'は', '、', '高度', 'な', '応', '答', 'が', '得', 'られる', '反', '面', '、', '基本的に', '有', '償', 'で', '利用', 'する必要があります', '。', 'ところで', '、', 'Hu', 'gging', 'Chat', '▁', 'という', 'サービスを', 'ご存知', 'でしょうか', '。', 'Hu', 'gging', 'Chat', '▁', 'は', '、', '様々な', '開発', '元', 'による', '多数', 'の', '言語', 'モデル', 'を', '自由に', '切り替え', 'て', '使用', 'できる', '、', '非常', 'に興味', '深い', 'プラ', 'ット', 'フォーム', 'です', '。', 'この', 'サービス', 'は', '驚', 'く', 'べき', 'ことに', '無', '償', 'で', '提供', 'されており', '、', '異なる', 'モデル', 'を', '手軽に', '試', 'す', 'ことができる', 'のが', '特徴', 'です', '。', 'ユーザー', 'は', '、', '各', 'モデル', 'の', '応', '答', 'の違い', 'や', '特性', 'を', '比較', 'しながら', '、', '自分の', '目的', 'に', '最適な', '言語', 'モデル', 'を選ぶ', 'ことができます', '。', '今回は', '、', 'この', '▁Hu', 'gging', 'Chat', '▁', 'を使って', '、', '</s>']
まず最初に注目すべきエラー、Token indices sequence length is longer than… が表示されるはずです。(このエラーは Python カーネル実行開始後、最初のエラーのときだけ表示されます。表示されないときは、Jupyter で Python カーネルをリセットしてみましょう。)
さて、このエラーは、sentence に含まれるトークンの数が tokenizer.model_max_length より多いときに出力されます。これは、tokenizer.model_max_length を大きくすれば回避できます。 しかし、トークナイザが正しくトークン化できたとしても、後処理の Sentence Transformer が、そのたくさんのトークンを一度に処理できるとは限らないので、その場合には max_position_embeddings より大きくしても無意味です。(後述のように、model.encode() を呼び出すときにエラーとなります。)
次に出力内容についてですが、いまのところは、tokens[“input_ids”] と convert_ids_to_tokens() の結果だけに着目しましょう。
tokens["input_ids"]:
- ここには、トークナイズされたテキストが数値(トークン ID)のリストとして格納されています。
- 各数値は、モデルが事前学習中に使用したボキャブラリ内の単語やサブワードに対応します。
- 例として、
sentence内のトークン “皆様” はトークン ID 90746 に変換されます。(私が実行したバージョンにて)
convert_ids_to_tokens():
convert_ids_to_tokens()を使うと、input_idsに含まれる トークンIDを再び文字列のトークンに変換できます。- これにより、トークナイザがどのようにテキストを分割したか、またどの単語やサブワードがどのトークン ID に対応するかを確認できます。
- 例として、90746 が “皆様” に変換されることが分かります。(私が実行したバージョンにて)
補足: Hugging Face Tokenizer API の進化
少し脇道に逸れますが、注意点を述べておきます。
Hugging Face のトークナイザ API では、v3 で新たに __call__ メソッドが追加されました。これにより、トークナイザを関数のように直接呼び出せるようになり、従来の tokenizer.tokenize() よりも柔軟で直感的に使えるようになりました。
__call__ は、Python の特殊メソッドの一つで、オブジェクトを関数のように呼び出すことを可能にします。具体的には、次のように書くことができます。
# トークナイザを関数のように呼び出す
tokens = tokenizer("This is a test.")
この tokenizer() の内部では __call__ メソッドが実行され、トークン化された結果(BatchEncoding オブジェクト)が返されます。
ポイント
- 従来:
tokenizer.tokenize()はトークンテキストのリストを返す単純な処理。 - 現在:
tokenizer()は、トークンIDやアテンションマスクを含むBatchEncodingを返す。このため、長いテキストの分割やモデル入力形式の生成も一度に処理できる。
まとめ
tokenizer.tokenize() を使うと、トークン化の結果だけが返され、分割情報やアテンションマスクなどが含まれません。
詳細はこちら:
以下では、従来 の tokenizer.tokenize() を使った例を示します。先ほどのコードと似ているので、混同しないようにしましょう。
tokens_trad = tokenizer.tokenize(sentence)
print("トークン化結果(従来の API):", tokens_trad)
結果:
トークン化結果(従来の API): ['▁', '皆様', 'は', '既に', '、', 'Open', 'AI', '▁', '社', 'の', '▁Chat', 'G', 'PT', '▁', 'を', '日', '頃', 'の', '業務', 'に', '活用', 'な', 'さ', 'っている', 'こと', 'と思います', '。', 'Chat', 'G', 'PT', '▁', 'は非常に', '優れた', 'サービス', 'ですが', '、', '当然', 'ながら', '、', 'Open', 'AI', '▁', '社', 'が', '開発', 'した', '大規模', '言語', 'モデル', '(', 'LL', 'M', ')', 'しか', '使用', 'できません', '。', 'G', 'PT', '-4', 'o', '▁', 'や', '▁o', '1-', 'p', 'review', '▁', 'といった', 'モデル', 'は', '、', '高度', 'な', '応', '答', 'が', '得', 'られる', '反', '面', '、', '基本的に', '有', '償', 'で', '利用', 'する必要があります', '。', 'ところで', '、', 'Hu', 'gging', 'Chat', '▁', 'という', 'サービスを', 'ご存知', 'でしょうか', '。', 'Hu', 'gging', 'Chat', '▁', 'は', '、', '様々な', '開発', '元', 'による', '多数', 'の', '言語', 'モデル', 'を', '自由に', '切り替え', 'て', '使用', 'できる', '、', '非常', 'に興味', '深い', 'プラ', 'ット', 'フォーム', 'です', '。', 'この', 'サービス', 'は', '驚', 'く', 'べき', 'ことに', '無', '償', 'で', '提供', 'されており', '、', '異なる', 'モデル', 'を', '手軽に', '試', 'す', 'ことができる', 'のが', '特徴', 'です', '。', 'ユーザー', 'は', '、', '各', 'モデル', 'の', '応', '答', 'の違い', 'や', '特性', 'を', '比較', 'しながら', '、', '自分の', '目的', 'に', '最適な', '言語', 'モデル', 'を選ぶ', 'ことができます', '。', '今回は', '、', 'この', '▁Hu', 'gging', 'Chat', '▁', 'を使って', '、']
max_seq_length を変えながら model.encode する
トークナイザの動きはおおよそ分かったので、今度は、特徴量を抽出する(embedding をする)Sentence Transformer の encode() メソッドについて、model.max_seq_length を変えながら動作の違いを見ていきましょう。
model.max_seq_length を変えることによって生成されるトークンの数が変わることは想像できますが、特徴量同士のコサイン類似度が変わってくること(テキストの類似度結果が異なること)も、同時に確認してみましょう。
max_seq_length が非常に小さい場合
まずは、model.max_seq_length を極端に短くしてみましょう。
model = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2")
model.max_seq_length = 10 # 非常に小さい場合
sentences = [
ORIG_SENTENCE,
"ChatGPT",
"最適な言語モデルを選ぶ",
]
embeddings = model.encode(sentences)
similarities = model.similarity(embeddings, embeddings)
print(similarities)
結果:
tensor([[1.0000, 0.1709, 0.2137],
[0.1709, 1.0000, 0.3097],
[0.2137, 0.3097, 1.0000]])
max_seq_length がデフォルト(128)の場合
次に、model.max_seq_length をデフォルトと同じにしてみましょう。
model.max_seq_length = 128 # デフォルトだが明示的に指定 embeddings = model.encode(sentences) similarities = model.similarity(embeddings, embeddings) print(similarities)
結果:
tensor([[1.0000, 0.6689, 0.4721],
[0.6689, 1.0000, 0.3097],
[0.4721, 0.3097, 1.0000]])
max_seq_length が最大(max_position_embeddings)の場合
次に、model.max_seq_length を最大(max_position_embeddings)にしてみましょう。
model.max_seq_length = 512 # config.max_position_embeddings まで大きくする embeddings = model.encode(sentences) similarities = model.similarity(embeddings, embeddings) print(similarities)
結果:
tensor([[1.0000, 0.5879, 0.5818],
[0.5879, 1.0000, 0.3097],
[0.5818, 0.3097, 1.0000]])
それぞれの場合で、similarities の結果が異なることが分かりました。
max_seq_length が大きすぎる場合
最後に、model.max_seq_length を max_position_embeddings よりも大きくしてみましょう。
model.max_seq_length = 513 # config.max_position_embeddings + 1 embeddings = model.encode(sentences) similarities = model.similarity(embeddings, embeddings) print(similarities)
結果:
tensor([[1.0000, 0.5879, 0.5818],
[0.5879, 1.0000, 0.3097],
[0.5818, 0.3097, 1.0000]])
意外かも知れませんが、sentences のどの要素も max_position_embeddings より短い場合は特に問題がないようです。つまり、sentences の要素が短ければ、トークナイザの出力が max_position_embeddings より大きくなることはないので、実行には差し支えないのでしょう。
sentences の要素が max_seq_length より長い場合
それでは、sentences[0] を 10倍の長さにしてみましょう。
%%capture # 以下の実行はエラーとなるので、%%capture で Jupyter でセル実行をエラーとして報告しないようにする sentences[0] = ORIG_SENTENCE * 10 # 最初のセンテンスをもっと長くしてみる embeddings = model.encode(sentences) similarities = model.similarity(embeddings, embeddings) print(similarities)
結果:
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[10], line 5
1 # 以下の実行はエラーとなるので、%%capture で Jupyter でセル実行をエラーとして報告しないようにする
3 sentences[0] = ORIG_SENTENCE * 10 # 最初のセンテンスをもっと長くしてみる
----> 5 embeddings = model.encode(sentences)
6 similarities = model.similarity(embeddings, embeddings)
7 print(similarities)
File ~/.pyenv/versions/3.11.8/envs/sentence_transformer/lib/python3.11/site-packages/sentence_transformers/SentenceTransformer.py:623, in SentenceTransformer.encode(self, sentences, prompt_name, prompt, batch_size, show_progress_bar, output_value, precision, convert_to_numpy, convert_to_tensor, device, normalize_embeddings, **kwargs)
620 features.update(extra_features)
622 with torch.no_grad():
--> 623 out_features = self.forward(features, **kwargs)
624 if self.device.type == "hpu":
625 out_features = copy.deepcopy(out_features)
File ~/.pyenv/versions/3.11.8/envs/sentence_transformer/lib/python3.11/site-packages/sentence_transformers/SentenceTransformer.py:690, in SentenceTransformer.forward(self, input, **kwargs)
688 module_kwarg_keys = self.module_kwargs.get(module_name, [])
689 module_kwargs = {key: value for key, value in kwargs.items() if key in module_kwarg_keys}
--> 690 input = module(input, **module_kwargs)
691 return input
File ~/.pyenv/versions/3.11.8/envs/sentence_transformer/lib/python3.11/site-packages/torch/nn/modules/module.py:1511, in Module._wrapped_call_impl(self, *args, **kwargs)
1509 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc]
1510 else:
-> 1511 return self._call_impl(*args, **kwargs)
File ~/.pyenv/versions/3.11.8/envs/sentence_transformer/lib/python3.11/site-packages/torch/nn/modules/module.py:1520, in Module._call_impl(self, *args, **kwargs)
1515 # If we don't have any hooks, we want to skip the rest of the logic in
1516 # this function, and just call forward.
1517 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1518 or _global_backward_pre_hooks or _global_backward_hooks
1519 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1520 return forward_call(*args, **kwargs)
1522 try:
1523 result = None
File ~/.pyenv/versions/3.11.8/envs/sentence_transformer/lib/python3.11/site-packages/sentence_transformers/models/Transformer.py:393, in Transformer.forward(self, features, **kwargs)
390 if "token_type_ids" in features:
391 trans_features["token_type_ids"] = features["token_type_ids"]
--> 393 output_states = self.auto_model(**trans_features, **kwargs, return_dict=False)
394 output_tokens = output_states[0]
396 # If the AutoModel is wrapped with a PeftModelForFeatureExtraction, then it may have added virtual tokens
397 # We need to extend the attention mask to include these virtual tokens, or the pooling will fail
File ~/.pyenv/versions/3.11.8/envs/sentence_transformer/lib/python3.11/site-packages/torch/nn/modules/module.py:1511, in Module._wrapped_call_impl(self, *args, **kwargs)
1509 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc]
1510 else:
-> 1511 return self._call_impl(*args, **kwargs)
File ~/.pyenv/versions/3.11.8/envs/sentence_transformer/lib/python3.11/site-packages/torch/nn/modules/module.py:1520, in Module._call_impl(self, *args, **kwargs)
1515 # If we don't have any hooks, we want to skip the rest of the logic in
1516 # this function, and just call forward.
1517 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1518 or _global_backward_pre_hooks or _global_backward_hooks
1519 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1520 return forward_call(*args, **kwargs)
1522 try:
1523 result = None
File ~/.pyenv/versions/3.11.8/envs/sentence_transformer/lib/python3.11/site-packages/transformers/models/bert/modeling_bert.py:1078, in BertModel.forward(self, input_ids, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds, encoder_hidden_states, encoder_attention_mask, past_key_values, use_cache, output_attentions, output_hidden_states, return_dict)
1075 else:
1076 token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
-> 1078 embedding_output = self.embeddings(
1079 input_ids=input_ids,
1080 position_ids=position_ids,
1081 token_type_ids=token_type_ids,
1082 inputs_embeds=inputs_embeds,
1083 past_key_values_length=past_key_values_length,
1084 )
1086 if attention_mask is None:
1087 attention_mask = torch.ones((batch_size, seq_length + past_key_values_length), device=device)
File ~/.pyenv/versions/3.11.8/envs/sentence_transformer/lib/python3.11/site-packages/torch/nn/modules/module.py:1511, in Module._wrapped_call_impl(self, *args, **kwargs)
1509 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc]
1510 else:
-> 1511 return self._call_impl(*args, **kwargs)
File ~/.pyenv/versions/3.11.8/envs/sentence_transformer/lib/python3.11/site-packages/torch/nn/modules/module.py:1520, in Module._call_impl(self, *args, **kwargs)
1515 # If we don't have any hooks, we want to skip the rest of the logic in
1516 # this function, and just call forward.
1517 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1518 or _global_backward_pre_hooks or _global_backward_hooks
1519 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1520 return forward_call(*args, **kwargs)
1522 try:
1523 result = None
File ~/.pyenv/versions/3.11.8/envs/sentence_transformer/lib/python3.11/site-packages/transformers/models/bert/modeling_bert.py:217, in BertEmbeddings.forward(self, input_ids, token_type_ids, position_ids, inputs_embeds, past_key_values_length)
215 if self.position_embedding_type == "absolute":
216 position_embeddings = self.position_embeddings(position_ids)
--> 217 embeddings += position_embeddings
218 embeddings = self.LayerNorm(embeddings)
219 embeddings = self.dropout(embeddings)
RuntimeError: The size of tensor a (513) must match the size of tensor b (512) at non-singleton dimension 1
これだと、やはりエラーになるようです。
RuntimeError: The size of tensor a (513) must match the size of tensor b (512) at non-singleton dimension 1 というエラーが表示されます。
ところで、この 512(max_position_embeddings)は、どうやったらプログラム中で確認できるでしょうか。
print("model.max_seq_length:", model.max_seq_length)
print(
"config.max_position_embeddings:",
model._first_module().auto_model.config.max_position_embeddings,
)
結果:
model.max_seq_length: 513 config.max_position_embeddings: 512
max_position_embeddings よりも長いテキストを処理するには?
ここまで見てきたように、Sentence Transformer のモデルには一度に処理できるトークンの数に制限があります。トークナイザにおいては、tokenizer.model_max_length というパラメタを増やすことによって、長いテキストから多くのトークンを出力することができますが、Sentence Transformer は深層ニューラルネットワークを使ったモデルであり、訓練時に使用したハイパーパラメータやモデル固有の設計によって、一度に処理できるトークン数が制約されます。この制限を簡単に変更することはできません。
一度に処理できるトークン数に制約のある Sentence Transformer を使いながら、複数の長いテキスト間の類似度を求めるにはどうしたら良いでしょうか?
一つの方法は、長いテキストを Sentence Transformer が一度に処理できるトークン数単位(セグメント)に分割し、Sentence Transformer を何回も呼び出していく、という方法です。Sentence Transformer は複数のセグメント毎に個別の特徴量ベクトル(embedding)を求めることになるので、それらの特徴量ベクトルをテキスト入力毎にたすき掛けで類似度を計算し、その結果の平均、あるいは最大値をもって、複数のテキスト間の類似度とする、というものです。
トークナイザの自動分割機能
Hugging Face のトークナイザには、長いテキストを自動的に分割する機能が備わっています。この機能を利用することで、モデルが処理可能なセグメント単位にテキストを分割することができます。以下のパラメータを用いることで、この機能を有効にします。
return_overflowing_tokens=Truemax_seq_lengthを超えるトークンを持つテキストを自動的に分割し、セグメントごとにトークンを返すようになります。
stride- セグメント間のトークンのオーバーラップを制御します。たとえば、
stride=10と設定すると、各セグメントの最後の 10トークンが次のセグメントの最初に再利用されます。
- セグメント間のトークンのオーバーラップを制御します。たとえば、
具体的には、例えば次のような手順となるでしょう。
ステップ1: テキストの分割
いま、sentences[0](テキスト0)と sentences[1](テキスト1)という 2つの長いテキスト(それぞれのトークン数が model.max_seq_length を超える)があります。
sentences[0] = "皆様は既に、OpenAI 社の ChatGPT を..." sentences[1] = "最近、ChatGPT との対話をブログで御紹介する..."
まず、各テキストをトークン化し、セグメント長(例: max_seq_length=256)とストライド(例: stride=10)を指定して、オーバーラップを持つセグメントに分割します。以下のようなデータ構造が得られます。各セグメントはテキスト形式で表現されます。
segmented_texts[0]: テキスト0 のセグメントのリストsegmented_texts[1]: テキスト1 のセグメントのリスト
ステップ2: 各セグメントの埋め込み計算
次に、セグメント化された各テキストに対して Sentence Transformer モデルを用いて特徴量ベクトル(embedding)を計算します。特徴量ベクトルは、各セグメントごとに生成され、以下のような形式で格納されます。これにより、各セグメントがベクトル空間内で表現されるようになります。
embeddings[0][j]: テキスト0 のセグメント j に対応する特徴量ベクトルembeddings[1][k]: テキスト1 のセグメント k に対応する特徴量ベクトル
ステップ3: 類似度行列の計算
各セグメント間のペアについてコサイン類似度を計算し、類似度行列 similarity_matrix を得ます。この行列の各行はテキスト0 のセグメント、各列はテキスト1 のセグメントに対応します。たとえば、similarity_matrix[i][j] はテキスト0 のセグメント i とテキスト1 のセグメント j の類似度を表します。
ステップ4: 類似度の統計
類似度行列から平均類似度や最大類似度を計算し、テキスト全体の類似度の指標として求めます。
実際のコード
まず、必要な関数を定義します。
tokenize_and_segment(): 長いテキストをトークン化し、指定された長さのセグメントに分割compute_embeddings(): セグメントごとに、特徴量ベクトル(embedding)を求める
視覚化のために、visualize_similarity_matrix() と truncate_label() も定義します。
関数定義
import japanize_matplotlib
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
# ヒートマップのラベル最大長を定義
MAX_LABEL_LEN = 10
def tokenize_and_segment(text, tokenizer, max_seq_length, stride):
"""
長いテキストをトークン化し、指定された長さのセグメントに分割する。
Parameters:
text (str): 入力テキスト。
tokenizer: Sentence Transformer のトークナイザ。
max_seq_length (int): 各セグメントの最大長。
stride (int): セグメント間の重複トークン数。
Returns:
list[str]: セグメント化されたテキストのリスト。
"""
tokens = tokenizer(
text,
truncation=True,
max_length=max_seq_length,
return_overflowing_tokens=True,
stride=stride,
)
# トークン ID をテキストにデコードしてリストで返す
return [
tokenizer.decode(segment, skip_special_tokens=True)
for segment in tokens["input_ids"]
]
def compute_embeddings(segmented_texts, model):
"""
各セグメントごとに Sentence Transformer を使用して埋め込みを計算する。
Parameters:
segmented_texts (list[list[str]]): セグメント化されたテキストのリスト。
model: Sentence Transformer モデル。
Returns:
list[np.ndarray]: 各セグメントの埋め込みベクトルリスト。
"""
# バッチ処理で埋め込みを計算
embeddings = [model.encode(segments) for segments in segmented_texts]
return embeddings
def truncate_label(label, max_length=MAX_LABEL_LEN):
"""
長いラベルを短縮して見やすくする。
Parameters:
label (str): 入力ラベル。
max_length (int): 最大文字数。
Returns:
str: 短縮されたラベル。
"""
return label[:max_length] + "..." if len(label) > max_length else label
def visualize_similarity_matrix(
similarity_matrix, text0_segments, text1_segments
):
"""
類似度行列をヒートマップ形式で視覚化する。
Parameters:
similarity_matrix (np.ndarray): 類似度行列。
text0_segments (list[str]): テキスト0のセグメントリスト。
text1_segments (list[str]): テキスト1のセグメントリスト。
"""
plt.figure(figsize=(8, 6))
sns.heatmap(
similarity_matrix,
annot=True,
fmt=".2f",
cmap="coolwarm",
xticklabels=[truncate_label(seg) for seg in text1_segments],
yticklabels=[truncate_label(seg) for seg in text0_segments],
cbar=True,
)
plt.ylabel("テキスト0のセグメント")
plt.xlabel("テキスト1のセグメント")
plt.title("類似度行列")
plt.xticks(rotation=45, ha="right")
plt.tight_layout()
plt.show()
モデルとトークナイザのロード
# モデルとトークナイザのロード
model = SentenceTransformer(
"sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
)
tokenizer = model.tokenizer
実際の処理
# サンプルテキスト
sentences = [
"皆様は既に、OpenAI 社の ChatGPT を日頃の業務に活用なさっていることと思います。",
"最近、ChatGPT との対話をブログで御紹介する機会が増えています。",
]
# デモ用に max_seq_length と stride を小さく設定
max_seq_length = 10
stride = 2
# 各テキストをセグメント化
segmented_texts = [
tokenize_and_segment(text, tokenizer, max_seq_length, stride)
for text in sentences
]
# 各テキストのセグメント化結果を番号付きで表示
print("セグメント化結果:")
for i, segments in enumerate(segmented_texts):
print(f"sentences[{i}] のセグメント:")
for j, segment in enumerate(segments):
print(f" セグメント[{j}]: {segment}")
# 各セグメントの埋め込みを計算
embeddings = compute_embeddings(segmented_texts, model)
# 各テキストの埋め込み結果を番号付きで表示
print("埋め込み結果:", [e.shape for e in embeddings])
for i, embedding in enumerate(embeddings):
print(f" sentences[{i}] の埋め込みベクトル数: {len(embedding)}")
# 類似度行列を計算
similarity_matrix = cosine_similarity(embeddings[0], embeddings[1])
print("\n類似度行列:")
print(np.round(similarity_matrix, 4))
# 平均類似度と最大類似度を計算
average_similarity = np.mean(similarity_matrix)
max_similarity = np.max(similarity_matrix)
print(f"\n平均類似度: {average_similarity:.4f}")
print(f"最大類似度: {max_similarity:.4f}")
結果:
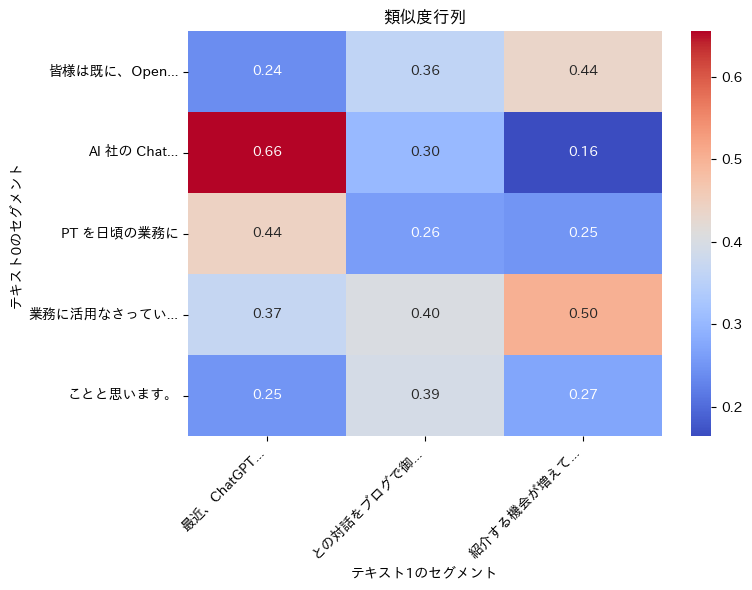
セグメント化結果: sentences[0] のセグメント: セグメント[0]: 皆様は既に、OpenAI セグメント[1]: AI 社の ChatGPT セグメント[2]: PT を日頃の業務に セグメント[3]: 業務に活用なさっていることと思います セグメント[4]: ことと思います。 sentences[1] のセグメント: セグメント[0]: 最近、ChatGPT との対 セグメント[1]: との対話をブログで御紹介する セグメント[2]: 紹介する機会が増えています。 埋め込み結果: [(5, 384), (3, 384)] sentences[0] の埋め込みベクトル数: 5 sentences[1] の埋め込みベクトル数: 3 類似度行列: [[0.2404 0.3614 0.4356] [0.6554 0.3039 0.1645] [0.4435 0.2619 0.2505] [0.3692 0.4034 0.5029] [0.2505 0.3937 0.2728]] 平均類似度: 0.3540 最大類似度: 0.6554
最後に、分かりやすく視覚化してみましょう。
# 類似度行列を視覚化
visualize_similarity_matrix(
similarity_matrix, segmented_texts[0], segmented_texts[1]
)
結果:
まとめ
このようにして、トークナイザの長いテキストの分割機能を使うことで、長いテキストを Sentence Transformer に入力できるようになりました。
JupyterLab のコード
まとめと次のステップ
本記事では、Sentence Transformer モデル paraphrase-multilingual-MiniLM-L12-v2 を使いながら、長いテキストの特徴量ベクトルを求める方法を紹介しました。しかし、Sentence Transformer の GitHub の Issues で次のような問い合わせをしたところ、設計時から長いテキストの処理が可能となっているモデルがあるそうです。
次回は、そこで紹介して頂いた別のモデルを使って、長いテキストの処理を試みたいと考えています。