Found some pros in Grafana though I impressed cons on it a few days ago.
先日 Elasticsearch Kibana と比較して Grafana の欠点をいくつか挙げましたが、Grafana にもいくつか活用方法があることが分かってきましたので、公平性の点からいくつか報告させて頂きたいと思います。
Grafana や Kibana など GUI 系の「データベース web 可視化ツール」には、プログラマ的人種には「痒いところに手が届かない」欠点がある一方で、プログラマでない方々が「20% の労力で 80% の効果を得られる」メリットがあります。また、Kibana の全機能を利用しようとすると有償サービスを利用せざるを得ませんが、Grafana は基本的に無償で全機能を使えそうですので、Grafana も活用していきたいところです。(特に、無償版の Kibana にはセキュリティ機能がないので、デモサイト等を公開するには有償サービスを使用せざるを得ません。もちろん、一番安価な選択肢を選ぶと US$ 15/月くらいから利用できそうですので、小企業にとっても投資額として十分安価だとは思いますが。)
ちょっと脱線
実は Dash + Plotly を勉強しようとして、こんなサイトを読んでいました。(Dash の紹介だけでなく、世の中の動向を非常によくサーベイしてらっしゃいますので、業界関係者の方には御一読をお勧めします。)
特に印象的なのは、
… But when it comes to data transformation and analytics, (これらの BI ツールは) it’s hard to beat the breadth and flexibility of programming languages and communities like Python…
というところで、GUI 的な BI(Business Intelligence という分野があるそうです)ツールと、Dash + Plotly のようなソフトウェアフレームワークは共存していくことになるのかなあ、という印象を持ちました。
閑話休題?
さて、Dash + Plotly のチュートリアルを読んでいて、以前からの疑問が再び頭をよぎりました。Kibana や Grafana を活用していくとして、時系列データを蓄えるのに(当面)どんなデータベースを活用していくべきなのだろうか、という点です。Kibana は Elasticsearch を前提としています。また、Python には Elasticsearch を利用するライブラリがありますので、例えば Pandas のデータフレーム作成に利用できそうです。
人間弱いもので、このような時にどうしても考えてしまうのは、「世の中では何か主流なのだろうか」ということです。つまり寄らば大樹の陰的な考えになってしまう訳です。さっそく Google でトレンドを調べてみました。
まずは、Grafana と関連付けてトレンドを見てみます。
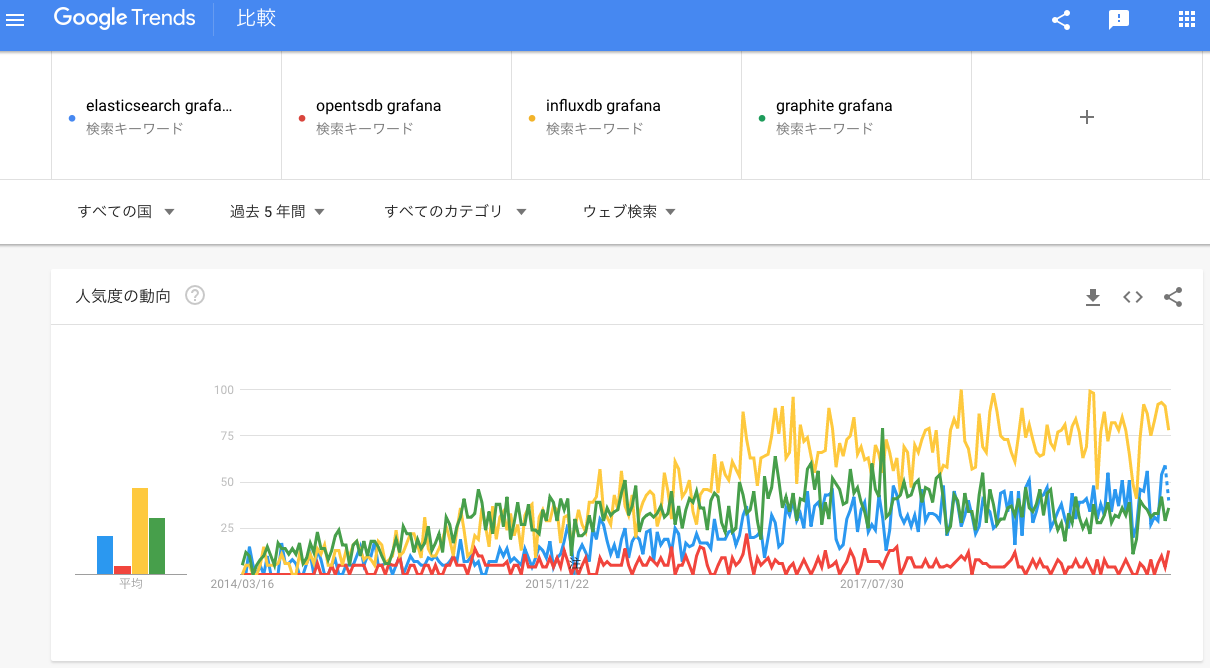
Grafana のコミュニティでは、InfluxDB の人気が高いようです。次に、pandas と関連付けて見てみます。
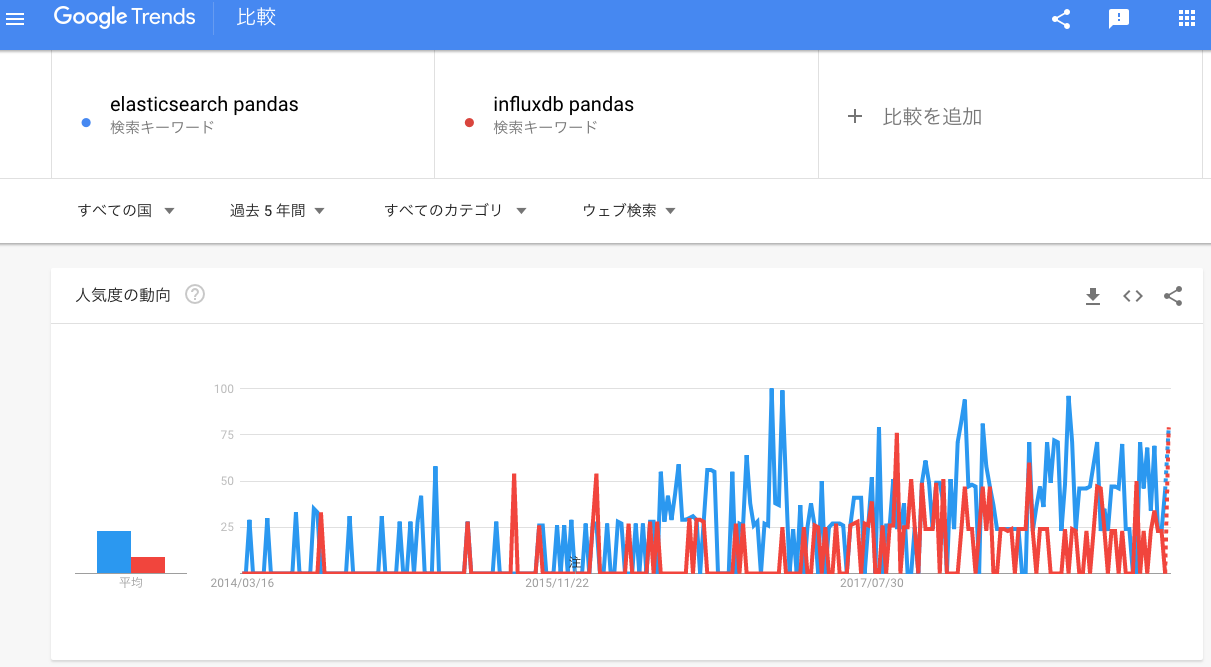
pandas のデータフレームとしては、Elasticsearch のほうが優勢のように見えます。せっかく Elasticsearch を勉強していることですし、しばらくは Elasticsearch で行ってみようと思います。(というか、Kibana は Elasticsearch の専用コンパニオンツールなので、Elasticsearch でしか利用できない。)
本当の閑話休題
前回、Grafana で MongoDB を利用しようとして(プラグインを探したりして)苦労したのですが、Elasticsearch はデフォルトで Grafana に対応しているので簡単です。
まずは、データソースを追加します。
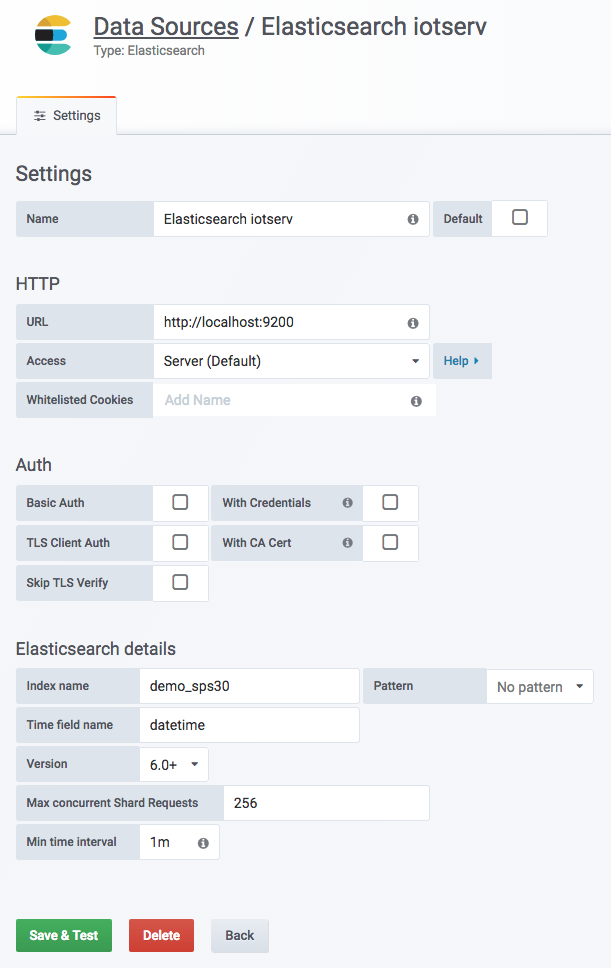
私のサイト(iotserv)では、件の PM 2.5 データを demo_sps30 というインデックスに格納しているので、Index name に demo_sps30 と入力します。時間軸フィールドは datetime なので、そのように変更します。Min time interval は「1分」としました。(データベースもそうなっています。)
次に、ダッシュボードの設計です。MongoDB の時は苦労したのですが、Elasticsearch では簡単です。
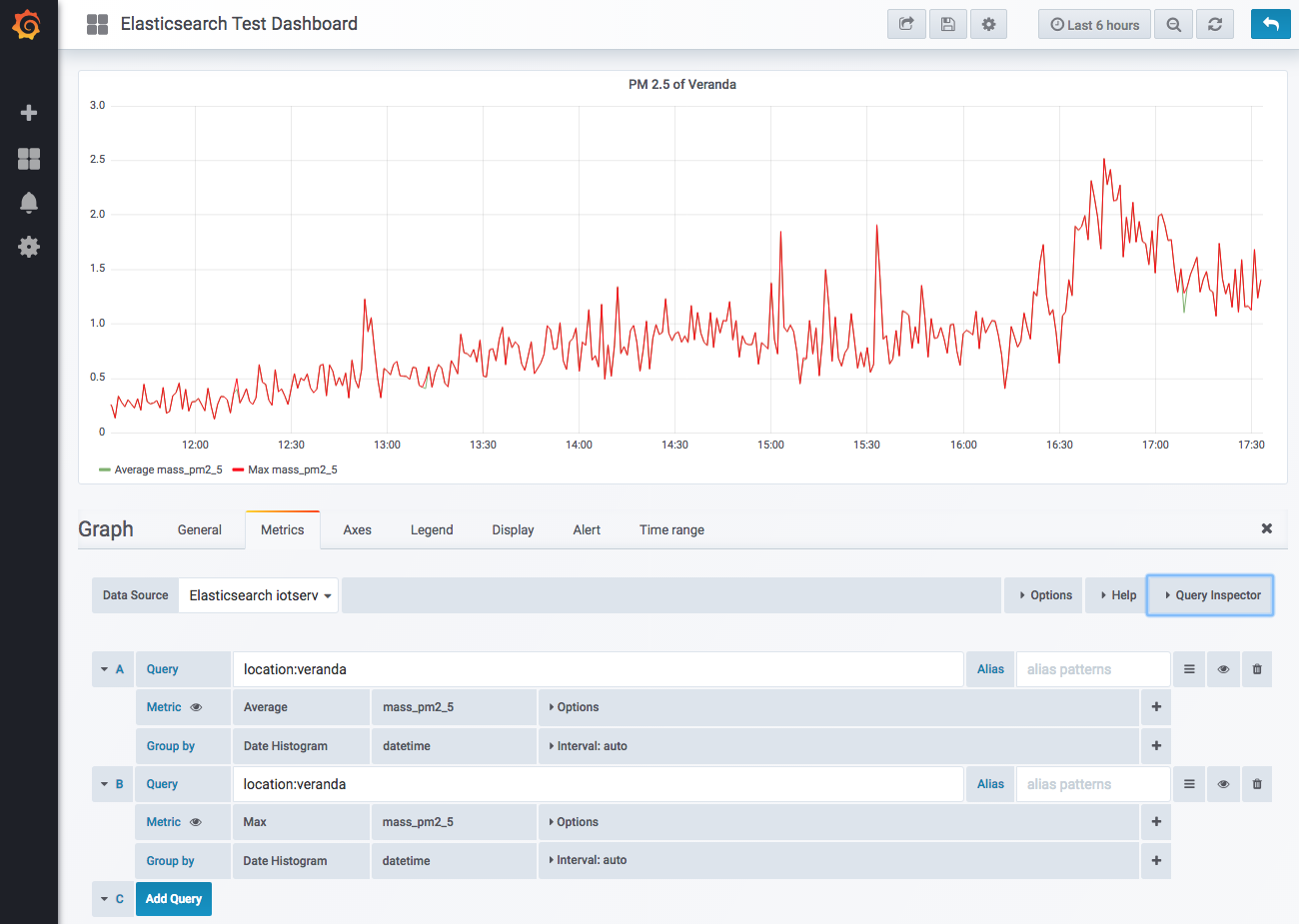
ここで驚いたのは、グラフの表示が極めて速いということです。これは正確に言うと、グラフの表示が速いというよりもデータベースへの query が効率的で速いということでしょう。
データベースへの query をインスペクタで覗いてみました。まだ Elasticsearch の REST API に不慣れなので読むのがしんどいのですが、エイっ。
{
"search_type": "query_then_fetch",
"ignore_unavailable": true,
"index": "demo_sps30",
"max_concurrent_shard_requests": 256
}
{
"size": 0,
"query": {
"bool": {
"filter": [
{
"range": {
"datetime": {
"gte": "1552271738843",
"lte": "1552293338844",
"format": "epoch_millis"
}
}
},
{
"query_string": {
"analyze_wildcard": true,
"query": "location:veranda"
}
}
]
}
},
"aggs": {
"2": {
"date_histogram": {
"interval": "1m",
"field": "datetime",
"min_doc_count": 0,
"extended_bounds": {
"min": "1552271738843",
"max": "1552293338844"
},
"format": "epoch_millis"
},
"aggs": {
"1": {
"avg": {
"field": "mass_pm2_5"
}
}
}
}
}
}
やや冗長な query に見えるのですが、ポイントは
"date_histogram": {
"interval": "1m",
"field": "datetime",
"min_doc_count": 0,
"extended_bounds": {
"min": "1552271738843",
"max": "1552293338844"
},
というところと、
"aggs": {
"1": {
"avg": {
"field": "mass_pm2_5"
}
}
}
ところのようです。前者では Elasticsearch の aggregation 機能を使って、時間軸上にヒストグラムを作成して複数の bucket(Elasticsearch の用語です。一般にヒストグラムの bin と呼ばれる概念と同じかと思います)に分割し、後者ではその結果である各 bucket の中で、 avg(平均値を計算する)という aggregation を実行し、それらをパイプラインで連結しています。
上記 query 要求をしてみると、(まだドキュメント数(つまりレコード数)が 11万ほどと小さなデータベースではありますが)Intel Celeron J3455(1.5GHz, ESXi 仮想メモリ 2GB)のサーバー(localhost)への問い合わせで 25ミリ秒程度で結果が返ってきます。十分に高速なのではないか、と思います。
今日のまとめ
というわけで、まずはお客様にデモをお見せして、反応を探ってみたいと思っています。
ダッシュボード全景
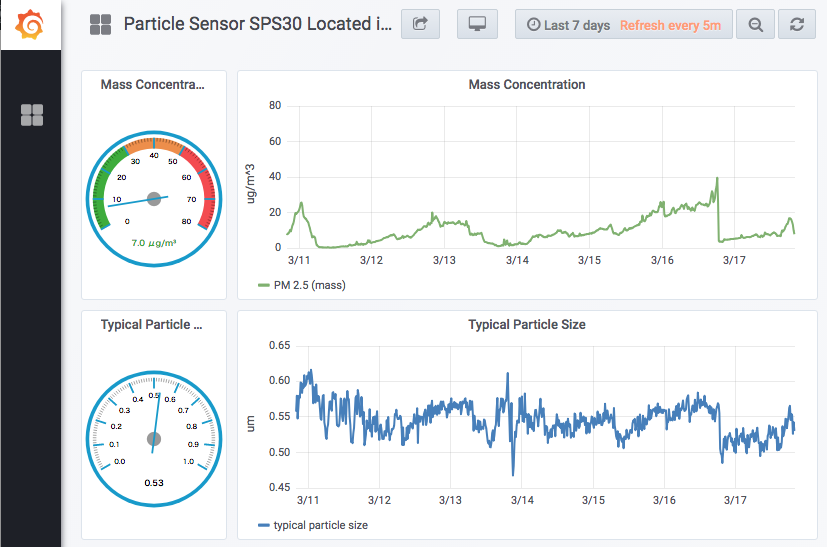
リアルタイムグラフ(iframe)
以下のリアルタイムグラフでは、マウスでドラッグすることで時間軸を拡大できます。ダブルクリックで縮小もできます。
お客様の反応が気になります…
もし「いいね 😎 」という反応が返ってきたら嬉しいですね。それでもダメなら Dash + Plotly でしょうか。「いやあ、うちは Excel で十分ですよ」とか言われると悲しいところですが、最初に引用した Introducing Dash でも、
… I like this example a lot because Excel still reigns supreme, even in technical computing and quantitative finance. I don’t think that Excel’s dominance is just a matter of technical ability. After all, there are legions of spreadsheet programmers who have learned the nuances of Excel, VBA, and even SQL…
と書かれていましたし、しようがないのかな、と複雑な心境ではあります。
今日はここまで。