Learn text embedding and similarity analysis with Sentence Transformer by Hugging Face. Covers Python code, multilingual model usage, and practical examples for mastering NLP techniques effectively.
相模原市で IoT 設計を受託しているファームロジックスです。
Sentence Transformerとは?
通常のテキスト検索では、「天気が良い」と「今日は晴れ」といった表現の違いを正確に捉えることが困難です。これらは単語レベルで一致しないため、一般的な検索アルゴリズムでは「無関係」と判断されてしまいます。
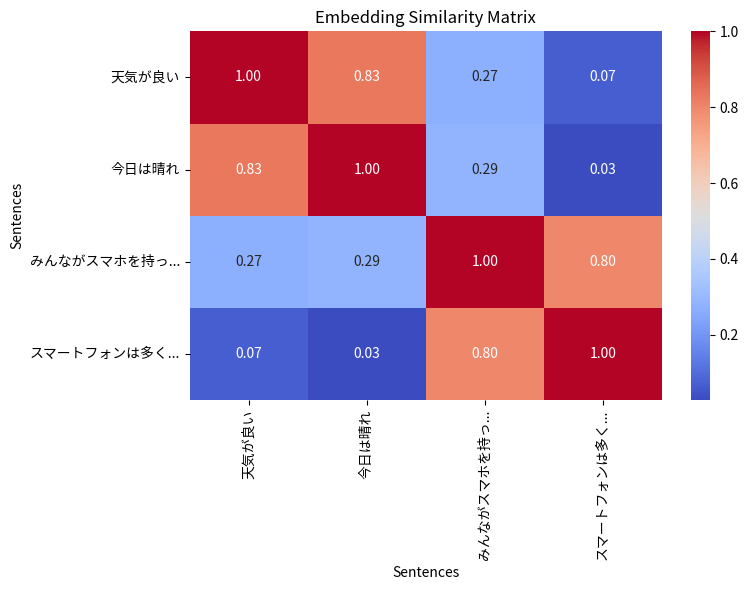
以下で詳細に入る前に、イメージを見たほうが後の理解の助けになるでしょう。いま、次のように 4つのテキストがあるとします。
- 天気が良い
- 今日は晴れ
- みんながスマホを持っている
- スマートフォンは多くの人が所有する
Sentence Transformer を使うと、冒頭で示したカラフルなチャートのように、テキスト間の類似度の組み合わせを求められます。縦軸と横軸の交差するときに、2つのテキストの類似度(どれだけ似ているか)が表示されています。赤いところは類似度が高く、青いところは低くなっています。
Hugging Face について
先日のブログでは、HuggingChat について紹介しました。HuggingChat は、Hugging Face が提供するオープンプラットフォームを活用して、様々な LLM(大規模言語モデル)を対話的に利用できるサービスです。その利便性を支えているのが、Hugging Faceの幅広いエコシステムです。
Hugging Face は、自然言語処理や画像認識をはじめとする AI モデルをローカル環境、リモートサーバー、さらにはサーバーレスで利用できる柔軟性を提供しています。その核となるのが Transformers ライブラリで、これを利用すれば最先端のモデルを簡単にロードし、タスクに応じてカスタマイズ可能です。また、Hugging Face Hub は、数多くの事前学習済みモデルやデータセットを共有するプラットフォームとして機能しています。
今回は、Hugging Face が提供する多くのモデルの中から Sentence Transformer と呼ばれるものに焦点を当てます。HuggingChat のようにモデルを対話に利用するのではなく、Python で書かれたプログラムを使って、テキストの特徴を埋め込みベクトルとして抽出し、それを活用した解析を行う点が特徴です。
これから、Sentence Transformer の基本的な使い方を紹介し、実際にテキストの埋め込みと類似度解析を試していきます。
Sentence Transformer は、文章やテキストを埋め込みベクトルとして表現するための機械学習モデルで、特に文間の意味的な類似度の計算や検索、クラスタリングに利用されます。少し難しい表現になりますが、文章全体の意味を embedding と呼ばれる高次元ベクトルとして表現することで、この問題を解決します。これにより、「天気が良い」と「今日は晴れ」のような異なる表現でも、高い類似度を持つベクトルとして計算できるのです。
今回は、SBERT.net というサイトを参考に、Sentence Transformer にトライしてみましょう。
Sentence Transformer は、必要なライブラリと環境セットアップ
早速、PC の上で動かしてみましょう。私は macOS を使用しましたが、Windows でも問題なく動作するはずです。Python は、3.9 以降が推奨のようです。
まず、pip を使って必要なライブラリをインストールします。
pip install --user "torch~=2.2" "sentence-transformers~=3.3" "numpy<2" "jupyterlab>=4" "ipywidgets" "seaborn~=0.13"
なお、JupyterLab と ipywidgets はオプションですが、JupyterLab 上での評価が便利でしょう。Jupyter については、ネットで検索の上、適宜チュートリアルを参照してください。
インストール上の注意点として、NumPy のバージョンとして <2.0 を指定しています。NumPy 2 は新しいバージョンで、まだ多くの関連ライブラリとの互換性の問題が見られます。
なお、以下で Python および JupyterLab のコード断片を示しますが、末尾に JupyterLab の完全なコードへのリンクを示しますので、そちらも併せて御利用ください。
Quickstart
早速、SBERT.net の Quickstart にあるコードを動かしてみましょう。
from sentence_transformers import SentenceTransformer
# 1. Load a pretrained Sentence Transformer model
model = SentenceTransformer("all-MiniLM-L6-v2")
# The sentences to encode
sentences = [
"The weather is lovely today.",
"It's so sunny outside!",
"He drove to the stadium.",
]
# 2. Calculate embeddings by calling model.encode()
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 384]
# 3. Calculate the embedding similarities
similarities = model.similarity(embeddings, embeddings)
print(similarities)
# tensor([[1.0000, 0.6660, 0.1046],
# [0.6660, 1.0000, 0.1411],
# [0.1046, 0.1411, 1.0000]])
コード中のコメントと同様、次のように表示されれば OK です。なお、tensor(テンソル)について詳しくは、PyTorch や TensorFlow など機械学習の入門書を参考にしてください。簡単に言うと、プログラミング言語の多次元配列のようなものだ、と考えれば雰囲気が分かるでしょう。
(3, 384)
tensor([[1.0000, 0.6660, 0.1046],
[0.6660, 1.0000, 0.1411],
[0.1046, 0.1411, 1.0000]])
詳細の確認
embedding とは
上のプログラムで計算している embedding(s) とはなんでしょう。これは、テキスト(上記で sentences の各要素)について、その特徴量を高次ベクトル(ここでは 384次)で表現したものです。以下では、上から順に sentences[0] 〜 sentences[2] のテキストの特徴量がベクトルで表示されています。
> print(embeddings) [[ 0.01919575 0.12008538 0.15959834 ... -0.00536288 -0.08109502 0.0502134 ] [-0.01869036 0.04151869 0.07431548 ... 0.00486597 -0.06190436 0.03187511] [ 0.136502 0.08227322 -0.02526164 ... 0.08762044 0.03045844 -0.01075753]]
類似度の計算
上記のコードのように、model.similarity() を使うと、各 embedding の間の類似度を求めることができます。デフォルトでは、コサイン類似度(cosine similarity)という尺度が計算されます。
コサイン類似度の基本的な考えは、高校の数学で教わる「ベクトルのなす角」を発展させたもので、2つのベクトルの内積をそれぞれのベクトルの大きさの積で除したものを類似度としています。(参考: Wikipedia)
原理的には、最も類似しているものは 1 \(=\cos(0)\) となり、類似性がないものは 0 \(=\cos(\pi/2)\)、まったく反対の意味を持つものは -1 \(=\cos(\pi)\) となります。(実際には、今回評価している Sentence Transformer では 0 以下の値はあまり出力されません。)
日本語でもやってみたい
先ほどのモデル all-MiniLM-L6-v2 は、英語のみをサポートしています。しかし多言語対応のモデルもあるので、それを試してみましょう。なお、同様の他のモデルについてはこちらに説明があります。
次のようなコードを実行してみましょう。(JupyterLab で評価することを前提に、既に実行したコード(import 文など)は省略しています。)
model = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2")
sentences = [
"The weather is lovely today.",
"It's so sunny outside!",
"He drove to the stadium.",
"今日は素晴らしい天気です。",
"外はとても日当たりが良いです!",
"彼はスタジアムまで車で行きました。",
]
embeddings = model.encode(sentences)
similarities = model.similarity(embeddings, embeddings)
print(similarities)
以下が結果です。
tensor([[1.0000, 0.8140, 0.1421, 0.9217, 0.8402, 0.1845],
[0.8140, 1.0000, 0.1580, 0.7513, 0.9221, 0.2022],
[0.1421, 0.1580, 1.0000, 0.1494, 0.1540, 0.8634],
[0.9217, 0.7513, 0.1494, 1.0000, 0.7693, 0.1644],
[0.8402, 0.9221, 0.1540, 0.7693, 1.0000, 0.2193],
[0.1845, 0.2022, 0.8634, 0.1644, 0.2193, 1.0000]])
結果を視覚的に表示したい
行列での表示は視認性が悪いので、ヘルパー関数 plot_similarity_heatmap を用意することにします。Matplotlib と Seaborn で書きます。
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import torch
from sklearn.metrics.pairwise import cosine_similarity
MAX_LEN = 10 # これ以上長いラベルは短くする
# 日本語フォントを設定
plt.rcParams["font.family"] = "Noto Sans CJK JP" # フォント名を指定
def plot_similarity_heatmap(sentences, embeddings_or_matrix, fmt=".2f", val=True):
"""
類似度マトリックスをプロットする関数
引数:
sentences (list[str]): センテンス(文)のリスト
ヒートマップのラベルとして使用されます。
長い場合は、先頭 MAX_LEN 文字に省略されます(デフォルトは10文字)。
embeddings_or_matrix (numpy.ndarray または torch.Tensor):
センテンスの埋め込みベクトル(複数)または既存の類似度マトリックス
embeddings を渡した場合、関数内部で類似度マトリックスが計算されます。
fmt (str, オプション): セル内の数値表示のフォーマット(例: ".2f")
デフォルトは小数点以下2桁を表示します。
val (bool, オプション): ヒートマップのセル内に数値を表示するかどうか
デフォルトは `True`(表示)。
"""
# Torch Tensor の場合、そのまま類似度マトリックスとして扱う
if isinstance(embeddings_or_matrix, torch.Tensor):
similarity_matrix = embeddings_or_matrix.detach().numpy()
else:
# NumPy 配列から類似度マトリックスを計算
similarity_matrix = cosine_similarity(embeddings_or_matrix)
# センテンスの行頭をラベルとして利用(長い場合は省略)
row_labels = [
sentence[:MAX_LEN] + "..." if len(sentence) > MAX_LEN else sentence
for sentence in sentences
]
# ヒートマップを作成
plt.figure(figsize=(8, 6)) # プロット全体のサイズを指定
sns.heatmap(
similarity_matrix, # プロットの形式
annot=val, # 各セルに数値を表示
fmt=fmt, # 数値のフォーマット
cmap="coolwarm", # カラーマップ(色のスケール)
xticklabels=row_labels, # X軸ラベル
yticklabels=row_labels, # Y軸ラベル
)
# プロットのタイトルと軸ラベルを設定
plt.title("Embedding Similarity Matrix") # タイトル
plt.xlabel("Sentences") # X軸ラベル
plt.ylabel("Sentences") # Y軸ラベル
# プロットを表示
plt.tight_layout() # レイアウト調整(ラベルが重ならないようにする)
plt.show()
実行してみましょう。
plot_similarity_heatmap(sentences, similarities)
次のようなヒートマップが表示されるはずです。
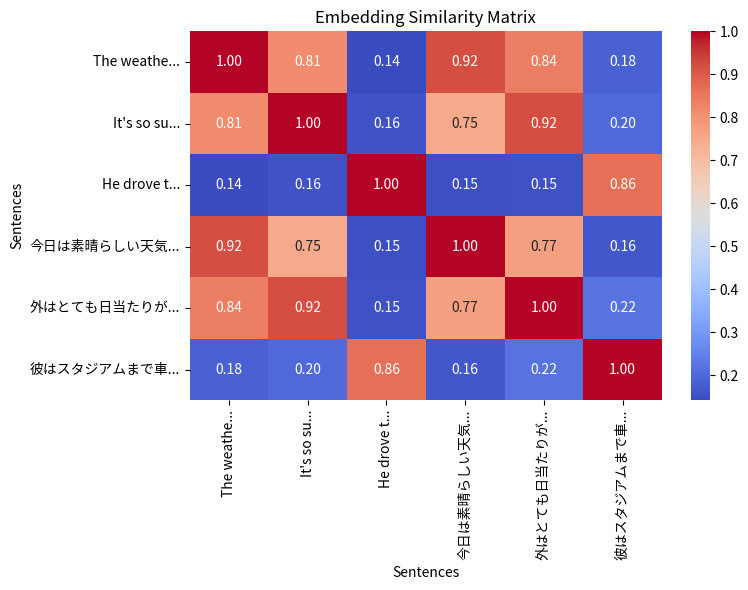
セルの値が大きい(1に近い)ものは、互いに類似度が高いことを示しています。同一の要素間の類似度は 1 なので、対角線上のセルには 1 が表示され、赤く塗られています。
興味深いことに、同じようなことを英語と日本語で書いたテキスト間は類似度が高くなっていますね。同じ言語間だけでなく、異なる言語間でも類似度を求めることができることが分かります。
応用例
ここで、いくつか応用例を考えてみましょう。
Google Tasks
Google Tasks というアプリを御存知でしょうか。Google 社が提供するもので、スマートフォンや PC でいわゆる「To Do リスト」を管理するためのものです。
このアプリはクラウドに同期しているので、スマートフォンでも PC でも同じリストにアクセスできるのは便利なのですが、致命的な問題は、アイテムの検索機能がないことです。そのため、一度入力したアイテムと似たようなアイテムを何度も追加してしまい、リストが溢れかえってしまうことが多いのです。同じようなことを御経験の方もあるのではないでしょうか。
Sentence Transformer を使って、この問題を解決できないでしょうか。まずは予備的な実験をしてみることにします。 以下のように、To Do リストを配列にまとめ、類似度をプロットしたみました。例に生活感がありすぎる点は、笑ってお許しください。🙂
ちなみに、実行に必要な演算時間を概観するため、Jupyter の magic コマンド%time で実行時間を測定しています。
sentences = [
"夕飯にスパゲティを作る",
"たまにはスパゲッティ料理",
"ミートソースのレシピ調べる",
"町田のラーメンを食べにいく",
"顧客に納期の問い合わせ",
"11月中にお客への確認",
"誕生日のプレゼント",
"12月1日: バースデイ",
"Making spaghetti",
"Inquiring with a customer",
]
%time embeddings = model.encode(sentences)
%time similarities = model.similarity(embeddings, embeddings)
# print(similarities)
plot_similarity_heatmap(sentences, similarities)
以下が結果です。
CPU times: user 291 ms, sys: 12.8 ms, total: 304 ms Wall time: 88.1 ms CPU times: user 1.78 ms, sys: 108 μs, total: 1.89 ms Wall time: 478 μs
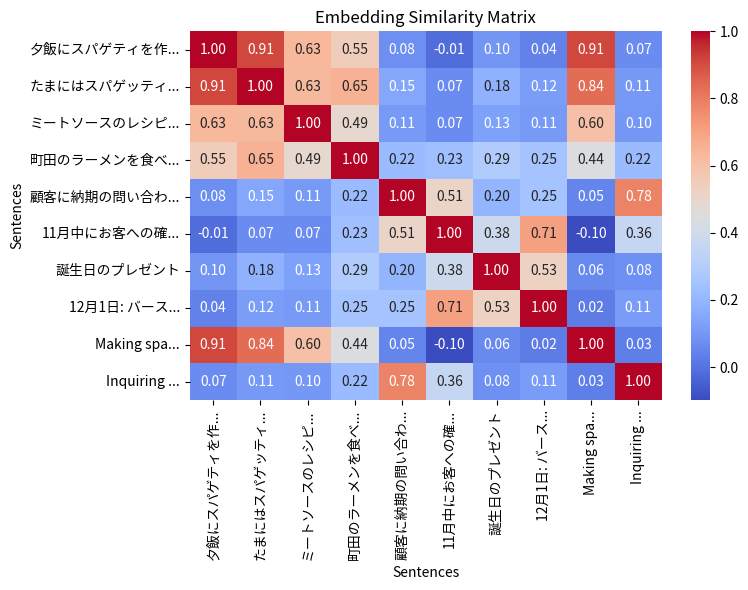
いかがでしょうか。
- 「スパゲティ」と「スパゲッティ」が同義であることを認識しています。このような単純な相違でも、通常のテキスト検索では難しいことが多いです。
- スパゲティとミートソースに関連があることを認識しています。
- スパゲティとラーメンにも一定の関連性(食べ物?)を認識しているようです。
- 思ったほど類似度が高くないが、顧客への問い合わせに関する 2つのアイテムに類似性を認識しています。
- 「11月中…」と「12月1日…」のアイテムは本来あまり関連ないのですが、類似度が高くなっています。どちらも日付を含むということからでしょうか。
- 先ほど試したように、日本語と英語の間でも、類似度が正しく求められています。
ブログ記事
ブログ記事に限りませんが、ネット上の記事では「この記事に類似した記事一覧」といったものがよく表示されます。Sentence Transformer でそのようなことは実現できないのでしょうか。試しに、私のブログからいくつかの記事を引用して、冒頭部分を取り出してテストしてみます。
なお、以下の結果では実際のブログ記事を簡単に確認するできるよう、予めリンクをまとめさせて頂きます。
- 皆様は既に、OpenAI 社の…
- 日々の業務の中で、組込デバイス…
- 今回は Python pip による,,,
- 以前に、AI イラストレーションの…
- 最近、ChatGPT との対話をブログで…
- リリースされたばかりの OpenAI o1…
- 組込ソフト設計者と回路設計 CAD…
- 最近、とある事情で、バイポーラ…
- 昨日は、愛知県春日井市にある大学に…
- Arduino のように小型で…
- ファームロジックスでは…
sentences = [
"皆様は既に、OpenAI 社の ChatGPT を日頃の業務に活用なさっていることと",
"日々の業務の中で、組込デバイス上のリアルタイムデータの可視化が必要になる",
"今回は Python pip によるパッケージ管理の話です。ちょっと便利なスクリプト",
"以前に、AI イラストレーションの新星、Black Forest Labs FLUX.1 について",
"最近、ChatGPT との対話をブログで御紹介する機会が増えています。皆様の中",
"リリースされたばかりの OpenAI o1 モデルを早速テストしてみました。",
"組込ソフト設計者と回路設計 CAD 組込ソフト設計を主業務としている",
"最近、とある事情で、バイポーラトランジスタを使った差動増幅回路の",
"昨日は、愛知県春日井市にある大学にお伺いし、TI のハイエンド DSP",
"Arduino のように小型で、日曜工作やラピッドプロトタイピングに便利な",
"ファームロジックスでは、組込設計の技術サポートから、若手技術者向けの",
"DSP",
"ChatGPT",
"CAD",
]
%time embeddings = model.encode(sentences)
similarities = model.similarity(embeddings, embeddings)
# print(similarities)
plot_similarity_heatmap(sentences, similarities, fmt=".1f")
註: 上記コードでは、sentences の長い行を省略しています。正式なコードは、末尾の JupyterLab ファイルへのリンクを参考にしてください。
補足(11月27日):
モデル paraphrase-multilingual-MiniLM-L12-v2 の max_seq_length はデフォルトで 128 に設定されており、長いテキストをモデルに渡すと128トークンを超える部分は切り捨てられます。(max_seq_length は、モデル定義の
sentence_bert_config.jsonに記述されています。)以下の続編では、長いテキストを処理する際の注意点について取り上げたいと思います。
さて、次のような結果が得られました。
CPU times: user 2.8 s, sys: 94.3 ms, total: 2.9 s Wall time: 742 ms
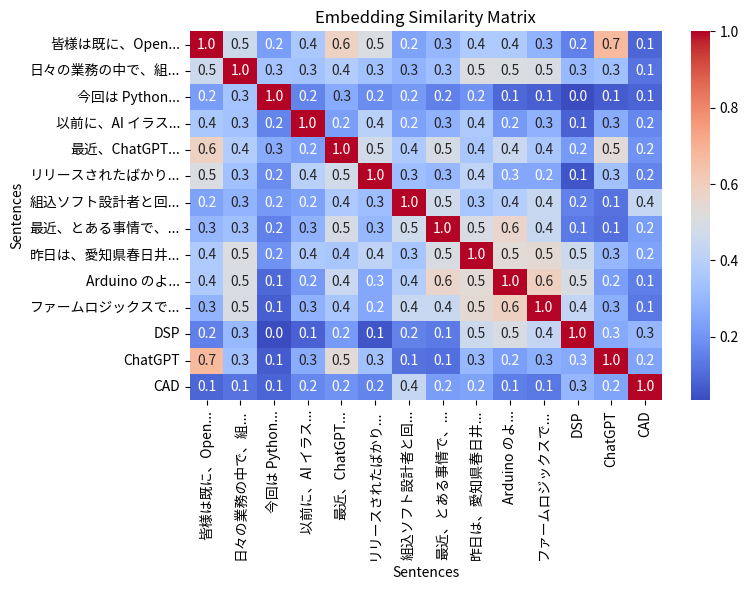
概ね期待通りの動作をしているようです。
なお、末尾の DSP, ChatGPT, CAD はテストのために追加しています。各記事にそれらの用語が関連するかどうかが分かるようになっています。
おまけ
下で示す JupyterLab のコードでは、いくつか実験的な例をまとめています。考察は省きますが、皆様もいろいろ試してみてください。
JupyterLab のコード
まとめと次のステップ
本記事では、Sentence Transformer を使ったテキスト埋め込みと類似度解析を実際に試し、その基礎的な使い方を解説しました。この技術を活用することで、タスク管理や検索システム、さらには文章推薦システムなど、さまざまな応用が可能です。
次の機会には、実際に Google Tasks にアクセスし、タスクアイテムの類似度を表示したりソートしたりするツールを作ってみたいと考えています。