Added SPI Peripheral functionality to Murax (free RISC-V SoC).
以前、TinyFPGA BX 上で動作する VexRiscv SoC Murax に PWM 機能を追加してみましたが、今回はもう少し実用的なペリフェラルとして、SPI ペリフェラルインターフェイスを追加してみました。目的の一つとして、クロックドメインをまたぐ設計を少し勉強してみたい、ということがあります。
SPI ペリフェラル機能の設計自身も、実は私の個人的興味から来ていて、以下のように機能を限定したバージョンになっています。
- COPI(SPI ペリフェラルとして受信機能)のみ
- ワード長は 16ビット固定
- SPI モードは 1 固定(CPOL = 0, CPHA = 1)
Clock Domain Crossing
クロックドメインをまたぐ、というのは、VexRiscv コアが動作するクロックとは別に、上記 SPI ペリフェラル回路を SPI マスタから送られてくる SPI クロックで動作させる、という意味です。私は HDL の設計は素人同然ですので、いろいろな資料を見ながら少し勉強しました。以下のサイトが参考になりました。
- Spinal HDL: Docs » Structuring » Clock domains
- SpinalHDL: Docs » Design errors » Clock crossing violation
- EE Times: Understanding Clock Domain Crossing Issues
ソースコード
SPI ペリフェラルを追加した Murax Soc のコードは、以下に置いておきました。
コードの説明
SpinalHDL による設計として、今までのブログで説明してこなかった点に絞って説明させて頂きます。
クロックドメインをまたぐ
まず最初に、SPI マスタからの SPI クロックで動作するクロックドメインを定義する必要があります。
val spi_clock_domain = ClockDomain(
clock = io.spi.sck,
reset = spi_reset,
config = ClockDomainConfig(
clockEdge = FALLING,
resetKind = ASYNC,
resetActiveLevel = HIGH
)
)spi_reset については、後で説明します。
clockEdge が FALLING というのは、今回の SPI ペリフェラルを SPI モード 1(CPOL = 0, CPHA = 1)で動かしたいためです。resetActiveLevel = HIGH というのは、(これが良い設計かどうか分からないのですが)このクロックドメインを、SPI の SS のアップエッジで非同期リセットしたい、という点にあります。
続いて、このクロックドメインで動作するエリア spi_clock_area を設計します。
val spi_clock_area = new ClockingArea(spi_clock_domain) {
val ct_bits = Counter(width)
val shift_reg = Reg(Bits(width bits)) init (0)
val output = Reg(Bits(width bits))
// We can't add "init(False)" to ct_full.
// Otherwise, spi.ss clears ct_full unintentionally.
val ct_full = Reg(Bool)
(略)で始まる部分ですね。
上述の SPI SS でリセットすべきレジスタと、そうでないレジスタに配慮して設計しています。(のつもりです。) フォーマル的な設計技術がないので、Verilator の波形を見ながら、かなり苦労してしまいました。一番悩んだのは、ct_full を SPI SS でリセットしたくないのだけど、電源投入直後に ct_full を False にリセットする方法が分からなかった点です。しようがないので、コアクロックドメインのほうに start というレジスタを設け、余計なデータが出力されないようにゲートすることにしました。(ふー)
もう一つは、シフトレジスタ shift_reg は SS でリセットしたいけど、コアクロックへ引き渡す output はクリアしたくない、という点でした。これもフォーマルというより、思いつきのアイデアでエイッと実現しました。(以下の部分)
val nextval = B(
width bits,
(width - 1 downto 1) -> shift_reg(width - 2 downto 0),
0 -> io.spi.mosi
)
when(ct_bits.willOverflow) {
output := nextval
} otherwise {
shift_reg := nextval
}
}HDL 設計の専門家でないわれわれが、この辺を理解するには、実際にシミュレータで動かして波形を見て頂くしかないと思います。(以下、クリックすると拡大できます)
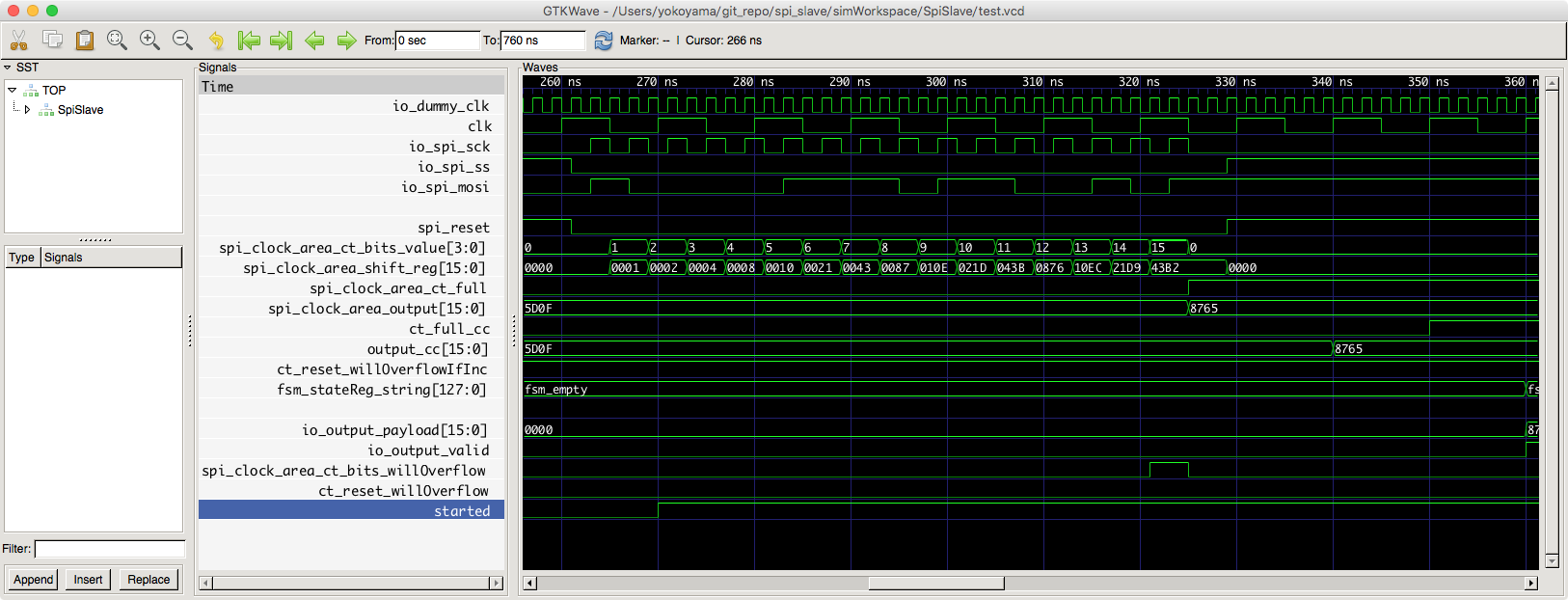
最後に、spi_clock_domain からコアクロックドメインに ct_full と output を引き渡す部分です。SpinalHDL のドキュメントでは、さらっと BufferCC と書いてますが、これはおそらく、buffer for clock crossing の略ではないかと思います。
val ct_full_cc = BufferCC(spi_clock_area.ct_full, bufferDepth = 3)
val output_cc = BufferCC(spi_clock_area.output)なお、クロックドメインをまたぐ部分で、output よりも先に ct_full が先にラッチされてしまうと困るので、ct_full_cc のほうの bufferDepth を 3 とし、output_cc よりも D-FF を 1つ多くしてあります。(デフォルトの bufferDepth は 2)
こんなんでいいんでしょうかね?(一応、動いてますけどね…)
あ、spi_reset の説明を忘れてました。spi_clock_domain のリセット入力は SPI SS による非同期リセットとしましたが、これは非同期と言っても、SPI SCK に同期していないというだけであり、エッジトリガである点は変わらないようです。つまり、SPI SS のアップエッジが来ないと、リセットされない訳ですね。
それでは困るので、電源が入ってから数サイクルの間、spi_reset を強制的に False(low)にしておくことにします。そのロジックが、こんな感じです。
val ct_reset = Counter(reset_wait)
when(!ct_reset.willOverflowIfInc) {
ct_reset.increment()
}
val spi_reset = ct_reset.willOverflowIfInc && io.spi.ss詳しくは、皆様もシミュレーションを動かし、波形を見てみてください。
複数クロックのシミュレーション
もう一つ、今回初めて複数クロックのシミュレーションをしてみました。SpinalHDL には分かりやすい例は見つからなかったのですが、リファレンスを見てでっち上げました。
まず、SpiSlave クラスにこんな記述をしておきます。
class SpiSlave(
width: Int,
reset_wait: Int = 3
) extends Component {
val io = new Bundle {
val spi = slave(Spi())
val output = master(Flow(Bits(width bits)))
val dummy_clk = in Bool // ← これと
}
(略)
/*
* For simulation purpose ↓ これ
*/
val dummy_sim_clock_domain = ClockDomain(
clock = io.dummy_clk
)このように記述しておくと、シミュレーションのほうで
val sim_clkdom = ClockDomain(dut.io.dummy_clk)という記述ができ、
def wait_sim(count: Int = 1) {
sim_clkdom.waitSampling(count)
}
sim_clkdom.forkStimulus(3)
dut.clockDomain.forkStimulus(period = 10)このようなことが書ける訳です。つまり、コアクロックよりも速く SPI SCK をパタパタさせられる訳ですね。
APB3 インターフェイス
次に、説明した SpiSlave クラスを Murax に繋ぐために、APB3 インターフェイスを書かなくてはなりません。以前に、PWM 用のインターフェイスを書いたので簡単かと思いきや、ちょっと、はまりました。
まずコードを示します。
class Apb3SpiSlave(width: Int, fifoDepth: Int = 8) extends Component {
val io = new Bundle {
val apb = slave(
Apb3(
addressWidth = 4,
dataWidth = 32
)
)
val spi = slave(Spi())
val interrupt = out Bool
}
val spislave = new SpiSlave(width)
io.spi <> spislave.io.spi
spislave.io.dummy_clk := False
val busCtrl = Apb3SlaveFactory(io.apb)
val q = spislave.io.output.toStream.queue(fifoDepth)
busCtrl.readStreamNonBlocking(
q,
address = 0,
validBitOffset = 31,
payloadBitOffset = 0
)
busCtrl.read(q.valid, address = 4, bitOffset = 0)
io.interrupt := q.valid
}spislave.io.output.toStream.queue(fifoDepth) というのは、SpiSlave の io.output(SpinalHDL の Flow)を Stream に変換し、さらに queue(FIFO)を挟むことを指示しています。さらに busCtrl.readStreamNonBlocking() を使うことで、SpiSlave の出力が Murax のメモリマップ上に見えるようになる訳です。簡単に記述できて便利ですね。
ところがひとつはまりました。最初は、実はこんなコードだったのです。(SpinalHDL のドキュメントにはありませんが、これでもビルドできます。)
val q = spislave.io.output.toStream.queue(fifoDepth)
busCtrl.readStreamNonBlocking(
q,
address = 0
)
Murax からこのアドレスを覗いてみると、SPI で受信したのとは違う値が見えてしまうのです。最初、SPI Peripheral の設計が悪いのかと思いました。なぜなら、Murax に繋ぐまで、SpiSlave クラスはシミュレーションでしか動作確認していなかったからです。デバッグ面倒だな、と思ったのですが、実は、readStreamNonBlocking() というのは特殊(?)で、validBitOffset 等を指定しない場合に、Stream からのデータを 1ビット左シフトした上で最下位に stream.valid ビットを付加してしまうのです。
そのため、私がテストすると、0x1234 は 0x2469 に、また 0x5555 は 0xaaab になったりと、奇妙な振る舞いをしたのでした。
最後に割込機能を付けました。これは、Murax や SpinalHDL のライブラリ UartCtrl を見て理解し、こんな風に書いています。
io.interrupt := q.valid分かってみれば簡単ですね。でも、この書き方がが分かるまで、SpinalHDL のコードをたくさん読むはめになりました。SpinalHDL のドキュメントに説明が欲しいところです。
実際に動かしてみる
以下に、実際に動かしてみたところを示します。FT232H ブレークアウトを繋いで Python スクリプト scripts/flogics/Murax/iCE40-tinyfpga-bx/scripts/spi_master.py を走らせると、UART にデータが出力され、次のようになりました。
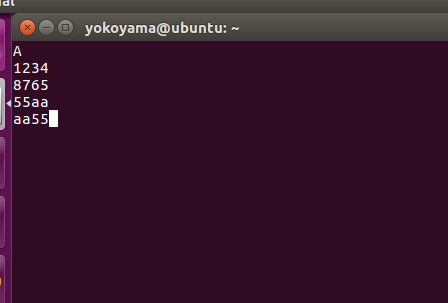
最初の「A」は文字化けではなくて、もともとの Murax デモコードで A を出力する部分があるのです。なお、SPI クロック速度ですが、FT232H がサポートしている最大周波数(?) 20MHz でも正しく動作することを確認できました。コアクロックは 16MHz ですので、当初のクロックドメイン勉強の目的を達成できたことになります。
いろんな機能が SpinalHDL で実現できるようになり、便利に使えそうな自信がついてきました。今日はここまで!