Now micro_speech training runs successfully with “micro” preprocess.
先日、”micro” preprocess(audio_microfrontend あるいは frontend_op オペレター付き)の TensorFlow をビルドできない話を書きましたが、ようやく無事に Docker 上でビルドできるようになりましたので、備忘録を兼ねてメモしておこうと思います。
何しろ micro_speech は experimental で、かつ(今日現在は)audio_microfrontend は Git の master ブランチ上にしかない機能なので、一月も経てば「古い話」になってしまうかも知れませんが、乞う御容赦。以下、手順です。
必要な Docker image を手に入れる
いろいろ試行錯誤しましたが、Docker image としては、初めから TensorFlow ライブラリが入っていない、カラッポの image が良いようです。カラッポと言っても、TensorFlow をビルドするために必要なツールが入っているものを使います。
なお、問題を難しくしている要因の一つはビルドツール Bazel の振る舞いの分かりづらさ、あるいは私が使い方を分かっていないこと(泣)です。具体的に言うと、bazel run を走らせる度に、何が不満なのか数時間のビルドをやり直ししてくれることです。これではいつまで経っても TensorFlow の train.py を走らせられません。この解決のため、カラッポの image ベースでビルドし、audio_microfrontend が入っている TensorFlow ライブラリをインストールした Docker image を用意すれば良いのではないか、と思いついた訳です。
閑話休題。image を入手します。
host$ docker pull tensorflow/tensorflow:devel-py3
なお、上記でタグ devel-py3 を指定してますが、私が試したのと完全に同じイメージを使いたい場合は、
host$ docker pull tensorflow/tensorflow@sha256:11a6468e11151cc1e967fd8c9a5bd5b0d394c90109cb6c58da93235c60ce63e2
してください。
Docker image を走らせる
私は Docker それほど詳しくないので、ここのコマンドラインオプションは、皆様のほうでいろいろ変更して頂いてもちろん OK です。 🙂
こちらを参考にしています。ホストの $HOME を繋いでいるのは、後で Speech Commands dataset を毎回ダウンロードしないようにしたいためです。詳しくは、ここで –data_url= を検索してみてください。
host$ docker run -it --name tf -w /tensorflow_src -v $HOME:/hosthome \
-e HOST_PERMS="$(id -u):$(id -g)" \
tensorflow/tensorflow:devel-py3 bash
なぜか devel 版ではバナーが表示されます。カッコいい。
TensorFlow を git pull する
docker:/tensorflow_src# git pull
ちなみに、私の動作確認したのはコミット 5bbeb08 です。なにぶん master には大量のコミットがあるので、情報がすぐに古くなってしまう可能性があります。
bazel ビルドする
後で(Docker コンテナ上に) pip でインストールしたいので、pip パッケージをビルドします。
docker:/tensorflow_src# bazel build -c opt //tensorflow/tools/pip_package:build_pip_package
私のホスト PC のプロセッサには FMA 命令セットは付いていないので、–copt=-mfma は付けていません。このビルドには大量のメモリを必要とします。私が docker stats で見ている感じでは、10GB 近いメモリを使ってました(割り当てた CPU は 7つ)。メモリが十分にない場合は、こちらを参考に –local_ram_resources オプションを使ってみてください。
補足: 私の Mac は Core i7-3770(Ivy Bridge)なので、CPU が持っている拡張命令セットを簡単に有効にするには、-copt=-march="ivybridge" を付けて、
# bazel build -c opt --copt=-march="ivybridge" //tensorflow/tools/pip_package:build_pip_package
とすると良いようです(参考)。ま、今回の speech_commands を学習してみた様子では、ぱっと見の大きな性能差はなさそうです。
pip インストール
2時間程度でビルドは終了しました。ちなみに使用したハードウェアは iMac Late 2012, Intel Core i7-3770 3.4 GHz(4 core + Hyper-threading)です。上述の通り Docker に CPU を 7つ、メモリは 12GB 与えてビルドしました。
続いて TensorFlow のインストールです。
docker:/tensorflow_src# ./bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp
docker:/tensorflow_src# pip install /tmp/tensorflow-1.14.0-cp36-cp36m-linux_x86_64.whl
ここまで作業したものを、Docker Hub の yokoyamaflogics/tensorflow:latest-frontend_op に置いておきます。。。
micro preprocess を試してみる
それでは早速、こちらに書かれている training を試してみましょう。
training ですが、もはや bazel run を使う必要はありません。こんな感じです。
docker:/tensorflow_src# python tensorflow/examples/speech_commands/train.py \
--model_architecture=tiny_conv --window_stride=20 --preprocess=micro \
--wanted_words="yes,no" --silence_percentage=25 --unknown_percentage=25 --quantize=1
ただしこれですと、実行する度に Speech Commands dataset を毎回ダウンロードしに行ってしまうので、データセットを予めホストの $HOME/dataset に展開してあれば、
docker:/tensorflow_src# python tensorflow/examples/speech_commands/train.py \
--data_url= --data_dir /hosthome/dataset \
--model_architecture=tiny_conv --window_stride=20 --preprocess=micro \
--wanted_words="yes,no" --silence_percentage=25 --unknown_percentage=25 --quantize=1
という形で、毎回ダウンロードをすることなく実行できます。
さて。3時間ほどで training も終わりました。こんな感じです。
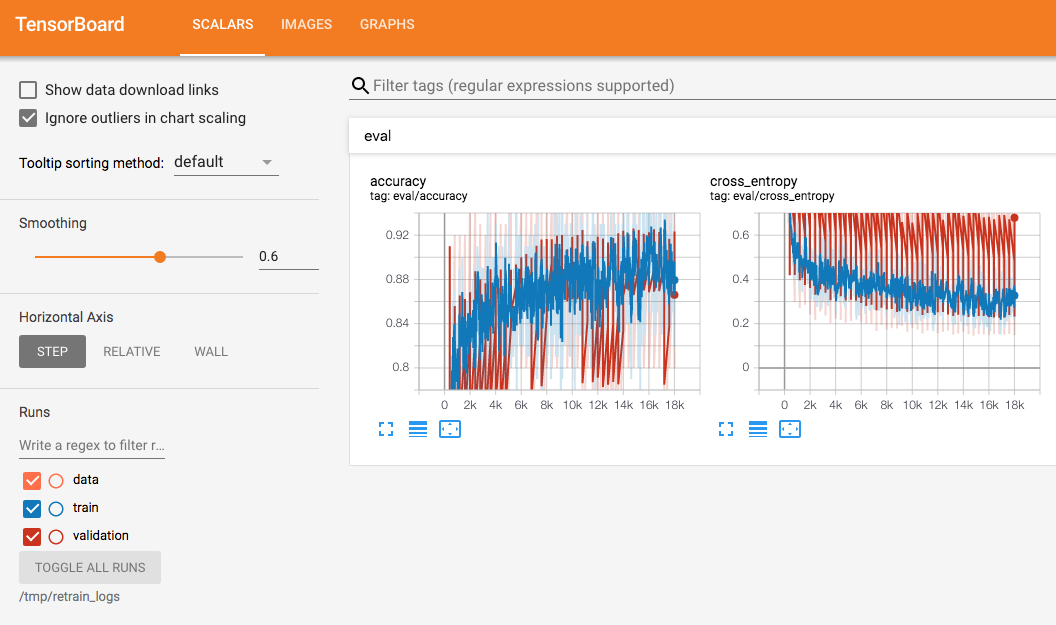
とりあえず、今日はここまで。次回は、変数の freezing も試してみたいと思います。しかし道のりは長い。いつになったら、手近なマイコンとマイクロホンを使って micro_speech できるのでしょう!
加筆(2019/07/06)
freeze したモデルを Netron で表示(一部)してみました。
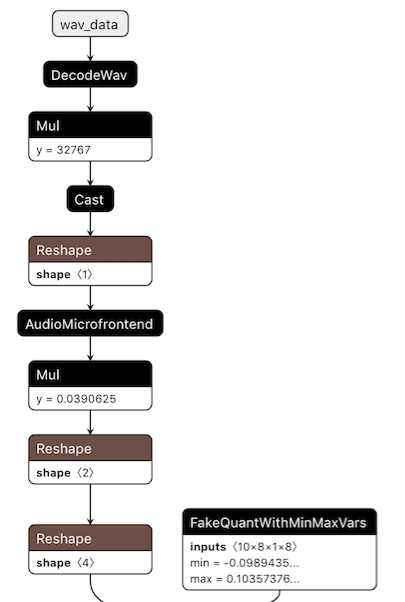
ちゃんと AudioMicrofrontend が入ってますね。ちなみに、FakeQuant… というのは、後でマイコンで動かすことを考えて入力テンソルを 8ビット量子化しているので、パラメタについても、学習時に 8ビット量子化で計算するためのものと想像しています。(勉強中)
toco で変換した結果です。(TensorFlow v1.9 以降では tflite_convert が標準らしいのですけど、同じオプションを与えるとうまくいかなくて、ちょっと工夫が必要です。これはまたいつか紹介します。)
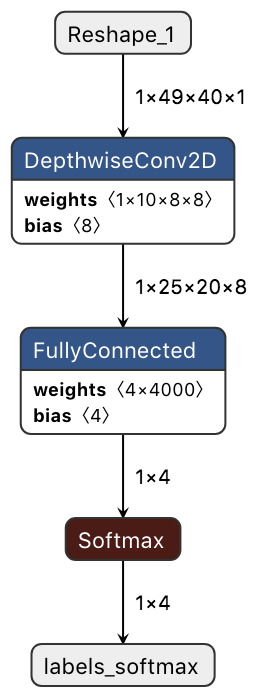
ところで、TensorFlow にカスタムなオペレターを追加する方法はこちらにありました。既存の TensorFlow v.1.14 に、これで audio_microfrontend を追加する、ということもできるのかも知れません。