FIFO design was harder than expected.
今回は、SpinalHDL を使って FIFO の設計をしてみることにします。
FIFO ってなに?
FIFO は、ソフト設計の世界ではキューと呼ばれることのほうが多いかも知れません。今回の私の興味としては、前回までに設計してきた UART との関係があります。例えば、UART 送信ブロックはシステムクロックの毎サイクルに送信データ(キャラクタ)を受け付けることはできません。UART が 1つのキャラクタを送信するには、ビットレートの逆数に(ワード長 + スタートビット長 + ストップビット長 + 必要ならばバリティビット長)を乗じた時間が必要だからです。送信元から勝手に次々と送信データを送りつけられては困るので、ハンドシェイクが必要になります。いっぽうで送信側(たとえば CPU)側としては、ソフトウェア的に CPU のサイクル毎にハンドシェイクの信号を監視するのは大変なので、できたらまとめて複数のキャラクタを同時に送信したいこともあるでしょう。その場合には、UART 送信回路に FIFO(キュー)があると便利です。
同様に UART の受信回路では、CPU が UART の受信回路のハンドシェイクを確認できない間に、外部から次々と受信データが送られてくると、受信データを取りこぼしてしまいます。そのため、多くのマイコンの UART 受信回路では、FIFO があるのが一般的です。(ただし、STM32 マイコンの一部では UART 受信 FIFO がなく、私は驚いたことがあります。) 有名かつ古典的な、FIFO 付き UART としては、National Semiconductor がオリジナルの 16550 があるかと思います。16550 は IBM PC および互換機で広く利用されたためか、マイコン製品のいくつかでは、この 16550 互換のレジスタセットを模したものを用意しているものがあるようです。
とりあえず自力で実装してみる
SpinalHDL には FIFO の実装(StreamFifo)があるのは知っていたのですが、これまた、それをそのまま利用してしまうと勉強にならないので、まずは自分で設計してみようと思いました。ハンドシェイクには、valid-ready バスを使います。
インターフェイスはこんな感じでしょうか。
class MyFifo(
width_payload: Int
) extends Component {
val io = new Bundle {
val src_valid = in Bool
val src_ready = out Bool
val src_payload = in Bits (width_payload bits)
val dst_valid = out Bool
val dst_ready = in Bool
val dst_payload = out Bits (width_payload bits)
}後で調べて、もっと一般的な用語で言うと、src は “source” で良いのですが、dst は “sink” と呼んだほうが良さそうです。さらに言うと、ここでの src は slave として振る舞い、dst は master として振る舞います。
さて。いろいろ書いてみたのは良いのですが、うまく FIFO になりません。ただの 1クロックディレイになってしまったり、path-through になったりしてしまいます。そもそも、FIFO に遅延は許されるのでしょうか。理論的には無遅延の FIFO も実現できそうですが、1サイクルの遅延が入っても良さそうです。
以下、苦労の一コマです。(FIFO になっていません!)
Combinational Loop
ところで、この苦労の過程で、一つ別の問題を見つけました。FIFO を設計して、先日までに作った UART 送信回路に繋いでテストベンチを動かそうとすると、SpinalHDL から combinational loop のエラーが出てしまうのです。このエラーの説明はここにあります。そこで挙げられているエラーのサンプルを引用します。
class TopLevel extends Component {
val a = UInt(8 bits) //PlayDev.scala line 831
val b = UInt(8 bits) //PlayDev.scala line 832
val c = UInt(8 bits)
val d = UInt(8 bits)
a := b
b := c | d
d := a
c := 0
}エラー出力の読み方ですが、慣れるまでちょっと分かりづらいです。上記の SpinalHDL 説明ページにある例でいうと、
COMBINATORIAL LOOP :
Partial chain :
>>> (toplevel/a : UInt[8 bits]) at ***(PlayDev.scala:831) >>>
意味: a を入力として出力を計算するよ
>>> (toplevel/d : UInt[8 bits]) at ***(PlayDev.scala:834) >>>
意味: その出力である d を入力として、ある出力を計算するよ
>>> (toplevel/b : UInt[8 bits]) at ***(PlayDev.scala:832) >>>
意味: その出力である b を入力として、ある出力を計算するよ
>>> (toplevel/a : UInt[8 bits]) at ***(PlayDev.scala:831) >>>
意味: ループして a に戻ってしまったよ
Full chain :
(toplevel/a : UInt[8 bits])
(toplevel/d : UInt[8 bits])
(UInt | UInt)[8 bits]
(toplevel/b : UInt[8 bits])
(toplevel/a : UInt[8 bits])
本当は、逆順にして a ← b ← d ← a(ループ検出)のように表示してくれたら分かりやすいのになあ、と思います。
なお、FIFO(valid-ready バス)設計における combinational loop については、こちらの説明が詳しいです。
簡単に言うと、source の valid 出力、sink の ready 出力が、組合せ回路(combinational logic)のループになると、その回路は動かないよ、論理合成できないよ、ということのようです。(何らかの方法で、ループ中に D-FF などが入れば良いのかな?)
カンニング
なんだか自分で FIFO を設計できる自信を失ったので、SpinalHDL の StreamFifo ライブラリをカンニングしてみました。SpinalHDL のバージョンは Git コミット a825423(たぶん v1.3.8 とほぼ同じ)です。
まず最初に、このライブラリを使って簡単な FIFO の実装(?)を書いてみます。こんなです。
import spinal.core._
import spinal.lib._
class LearnFifo(
width_payload: Int
) extends Component {
val io = new Bundle {
val src = slave Stream (Bits(width_payload bits))
val dst = master Stream (Bits(width_payload bits))
}
io.src.m2sPipe() >> io.dst
}Stream というのは、例の valid-ready バスのことです。バス中の payload として、Bits(width_payload bits) 型を使いますよ、と宣言しています。また、slave というのは、自分から見て slave 側だよ、master はその逆です。これは、後述の
io.src.m2sPipe() >> io.dstで必要になるのだと思います。ここで「>>」を説明する前に、まず最初に m2sPipe() から説明しなくてはいけません。m2sPipe() というのは、指定した Stream オブジェクト(ここでは io.src)に対して 1段の深さの FIFO を後ろに繋ぐ、という意味のようです。そして、「>>」を使うことで、その Stream の出力(sink)を io.dst に繋いでね、ということになります。
ちなみにドキュメントを読むと、m2sPipe() の代わりに s2mPipe() というのもあります。違いはドキュメントを読んでもよく分かりませんが、明確な違いとして、前者は FIFO のレイテンシが 1クロックなのに対し、後者は 0クロックだということがあります。
さらに加えて、queue() というものがあり、これを使うと任意の段数の FIFO を実現できます。なお、ここで述べたやり方で slave Stream に m2sPipe(), s2mPipe(), queue() などを使って FIFO を構成する代わりに、StreamFifo というユーティリティクラスを使って FIFO を構成することもできます。実は、上述の queue() というメンバ関数は、内部で StreamFifo クラスのオブジェクトを生成しています。
余談ですが、StreamFifo クラスの実装を読むと、興味深いことが分かります。それは、インスタンス化パラメタ depth によって、FIFO の実現方法を選択しているということです。depth が 0 のときは、前段と後段の Stream を直結します。1 のときは、m2sPipe() で繋ぎます。それより大きいときは、メモリと push/pop ポインタを使った実装を使います。depth が 2以上のときの StreamFifo のレイテンシは 2固定になるようです。この辺は、今後機会があったらもう少し勉強してみたいと思います。
シミュレーションしてみる
さて。m2sPipe() を使った、上述の LearnFifo をシミュレーションしてみましょう。テストベンチのコードは省略しますが、雰囲気はお分かり頂けるかと思います。(クリックすると拡大できます)
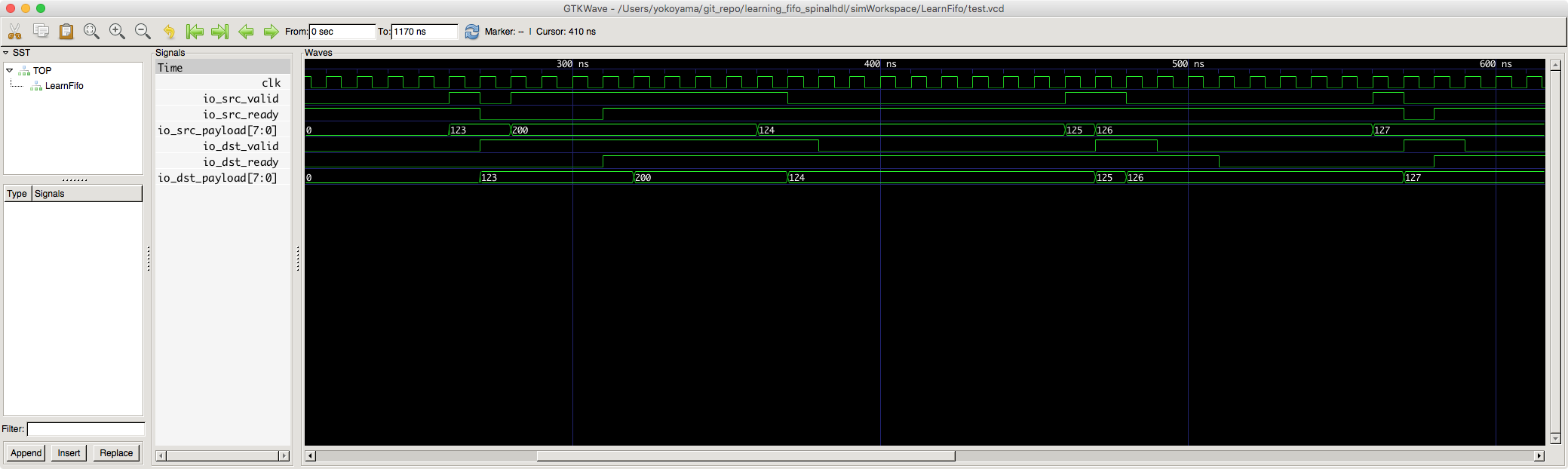
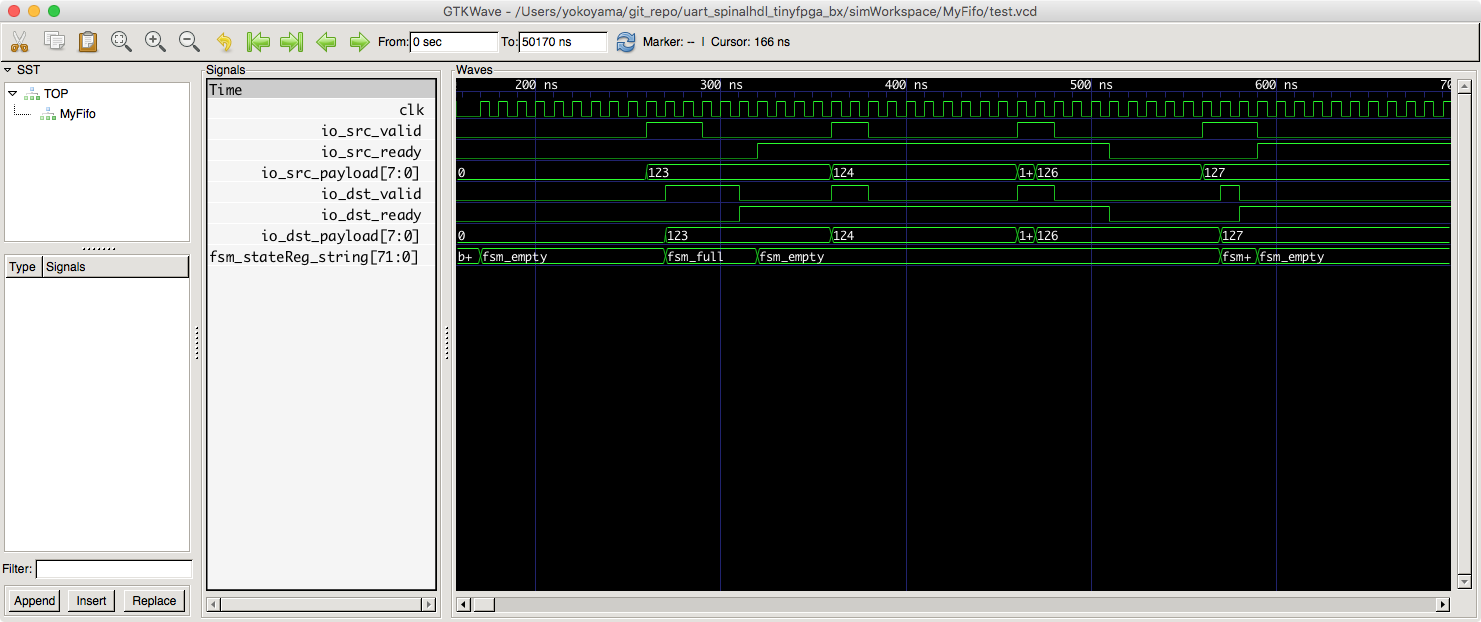
時刻 280ns 辺りを見ると、io.dst_ready が False にも関わらず、最初の payload = 123 の送出を完了し、次の payload = 200 の valid サイクルに入っていることが分かります。
今後は、s2mPipe() を使ってみます。
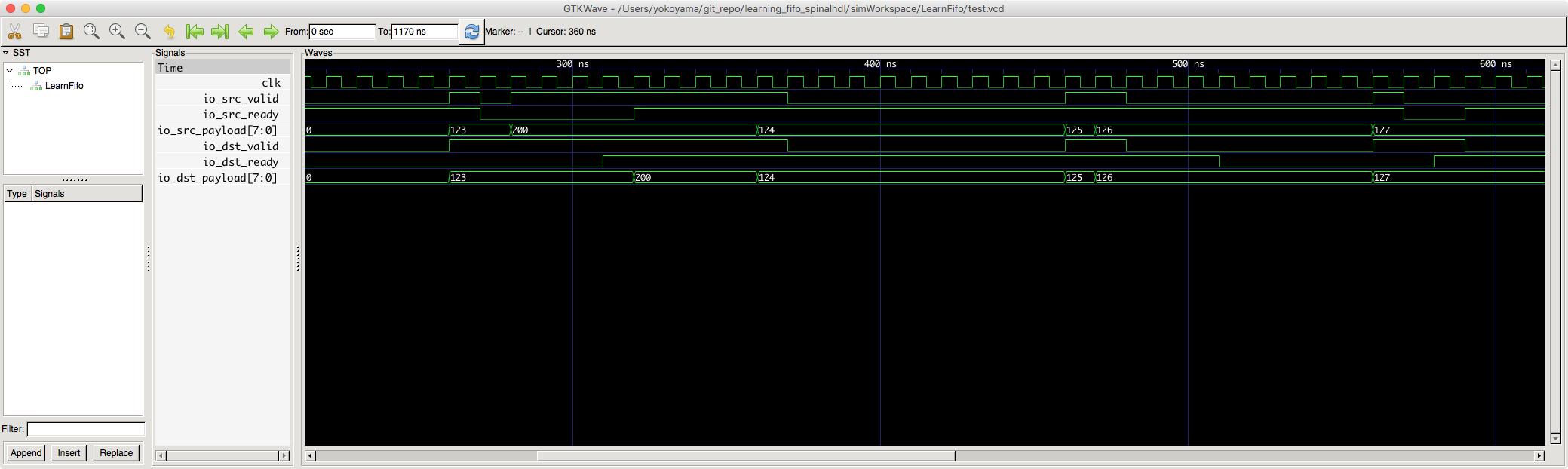
今度は、レイテンシ無しで FIFO が実現されていることが分かります。
SpinalHDL FIFO の設計を調べてみる
さて、このような m2sPipe(), s2mPipe() はどのように設計されているのか気になりますよね。コードは、この辺にあるので興味のある方は読んでみてください。私は大いに興味があったので、論理回路図にまとめてみました。私は論理回路屋でないので、変な記述があったら許してください。台形が横を向いているのはマルチプレクサで、四角いのは D フリップフロップですね。
また余談: 回路図のようなビジュアル表現(?)にする利点としては、論理をイメージとして頭の中に想起しやすいことではないでしょうか。理解できていないとしても、必要なときに回路図を頭に描き出すことができるので、もう一度手を動かして検証したり勉強したりすることができます。
ソフト屋という人間は、なんでもビジュアルではなくテキスト表現で記述することが美しいと思いがちですが、テキスト表現の欠点は、後で想起が難しいことです。ま、これは人によって異なるのかも知れませんね。私は物事を記述するのはテキスト表現が好きですが、ぱっとイメージを想起するのは、ビジュアル表現によるほうが得意です。

m2sPipe() もけっこう難しいと思うのですが、s2mPipe() は、もはや理解しようとする気力すら失いました。 🙂
一つだけ分かったことは、valid と ready の間のパスは combinational logic になっておらず、combinational loop にならないようになっている、ということです。当たり前なのかも知れませんが。
さて。m2sPipe() の設計だけでも理解したいと思い、シミュレーション波形を横に置きながら、しばらく回路図を眺めてみました。しかし、波形から直感的にこの論理回路を設計するのは困難だということが分かりました。(経験豊富な設計者さんは、直感的に書けるのかも知れませんが)
何か、もっとフォーマルなやり方で、この回路を演繹できないものでしょうか。しばらくして、思いつきました。学生時代の論理回路の講義で、真理値表を使って全ての入力組合せと状態を列挙して、順序回路を設計するという方法を習ったはずです。教科書は、もうどこかに行ってしまいましたが、ネットを探せば参考資料は見つかることでしょう。
上記の m2sPipe の回路では、(payload を除くと)入力信号は 2本(src.valid と sink.ready)しかありません。また、D-FF が 2つ、これも payload を除くと1つですので、内部状態は 2通りです。結果としては、真理値表で 8種類の論理だけ列挙すれば、全ての入力と状態を網羅できそうです。
次回は、真理値表を使って、上記 m2sPipe の設計を繙いてみたいと思います。なんだかかなり脱線してきて、FIFO に関しては SpinalHDL をそのまま使えば良いような気もしますが、悔しいのでもうしらばくお付き合いください。
今日はここまで。