Tried MNIST handwritten digits recognition,which was trained by Keras, by Neural Network on STM32 microcontroller,.
今日は、機械学習フレームワーク Keras で学習させたニューラルネットを STM32 マイコンにロードし、マイコンで手書き数字(MNIST データセット)を識別をしてみました。結論から言いますと、学習データ 400キロバイト程度をフラッシュメモリに書き込み、正しく手書き文字を識別できることを確認しました。

最近、Google 社から TensorFlow Lite for Microcontrollers というフレームワークが発表され(現状は experimental)、マイコンでのニューラルネット活用が進んでいますが、今回は STMicroelectronics から今年初旬にリリースされた X-CUBE-AI というツールキットを評価してみることにしました。
 (X-CUBE-AI – AI expansion pack for STM32CubeMX – STMicroelectronics より)
(X-CUBE-AI – AI expansion pack for STM32CubeMX – STMicroelectronics より)
この X-CUBE-AI は、TensorFlow Lite とは独立に設計されているようで、Keras や Lasagne、Caffe、ConvNetJs といった機械学習フレームワークで作成および学習したモデルを変換することができます。変換した結果(ソフトウェアプロジェクト)は、同社のさまざまな STM32 マイコン上で実行することができます。(ARM Cortex-M4 以上が必要のようです。)
今回は、Keras にて簡単な全結合のニューラルネットを設計、またパソコン上で学習させた後、出力されたモデルファイルを X-CUBE-AI を使って STM32 マイコンボード(Nucleo-144 STM32F429)に載せ、手書き数字の推論をさせてみました。このマイコンボードで直接手書き数字を直接(カメラやディジタイザで)読み取れればカッコイイのですが、残念ながらそのようなペリフェラルがないので、MNIST データセット上のテストサンプルを 10個ほど C 言語のヘッダファイル形式で出力し、マイコンで推論させてみることにします。
ちなみに MNIST データセットというのは、次のようなものです。

Keras でモデルを設計および学習してみる
Keras を使って MNIST 手書き数字を識別する例としては、TensorFlow のサイトで紹介されている以下のチュートリアルが非常に参考になります。
チュートリアルでは Fashion MNIST dataset を使ってますが、私はこれがいまひとつ好きでないので(ファッション用語に弱いから 🙂 )、普通の手書き数字データセットを使いました。
また、これは最初にハマったのですが、現状の X-CUBE-AI(v3.4.0)では、TensorFlow 上の Keras が出力する 2.2.4-tf モデルファイルは読み込むことができず、オリジナルの Keras で出力したモデルファイル(2.2.4 フォーマット)でないと処理できません。
以下、Keras(2.2.4)のコードを示します。ほとんど上記チュートリアルのままですので、内容についてはそちらの説明を御覧ください。
import keras
from keras import backend as K
digits_mnist = keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = \
digits_mnist.load_data()
train_images = train_images / 255.0
test_images = test_images / 255.0
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation=K.relu),
keras.layers.Dense(10, activation=K.softmax)
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=5)
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('Test accuracy:', test_acc)
model.save('mnist_digits.h5')
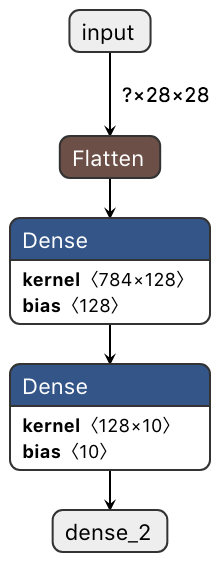
これを Python3 で実行すると、mnist_digits.h5 というモデルファイルが得られます。Netron でちょっと覗いてみましょう。こんな感じです。
X-CUBE-AI でモデルを取り込む
X-CUBE-AI ですが、これは同社の STM32CubeMX というツールキットの拡張パックとなっています。STM32CubeMX は、マイコンソフトの設計時に頭の痛い様々な問題を解決してくれるツールで、最近 STMicroelectronics 社が力を入れているものです。(ただし、このようなパワーツールあるいはウィザードツールが嫌いな設計者もいます。私も実はあまり好きではないけど、便利なので使っちゃう。)
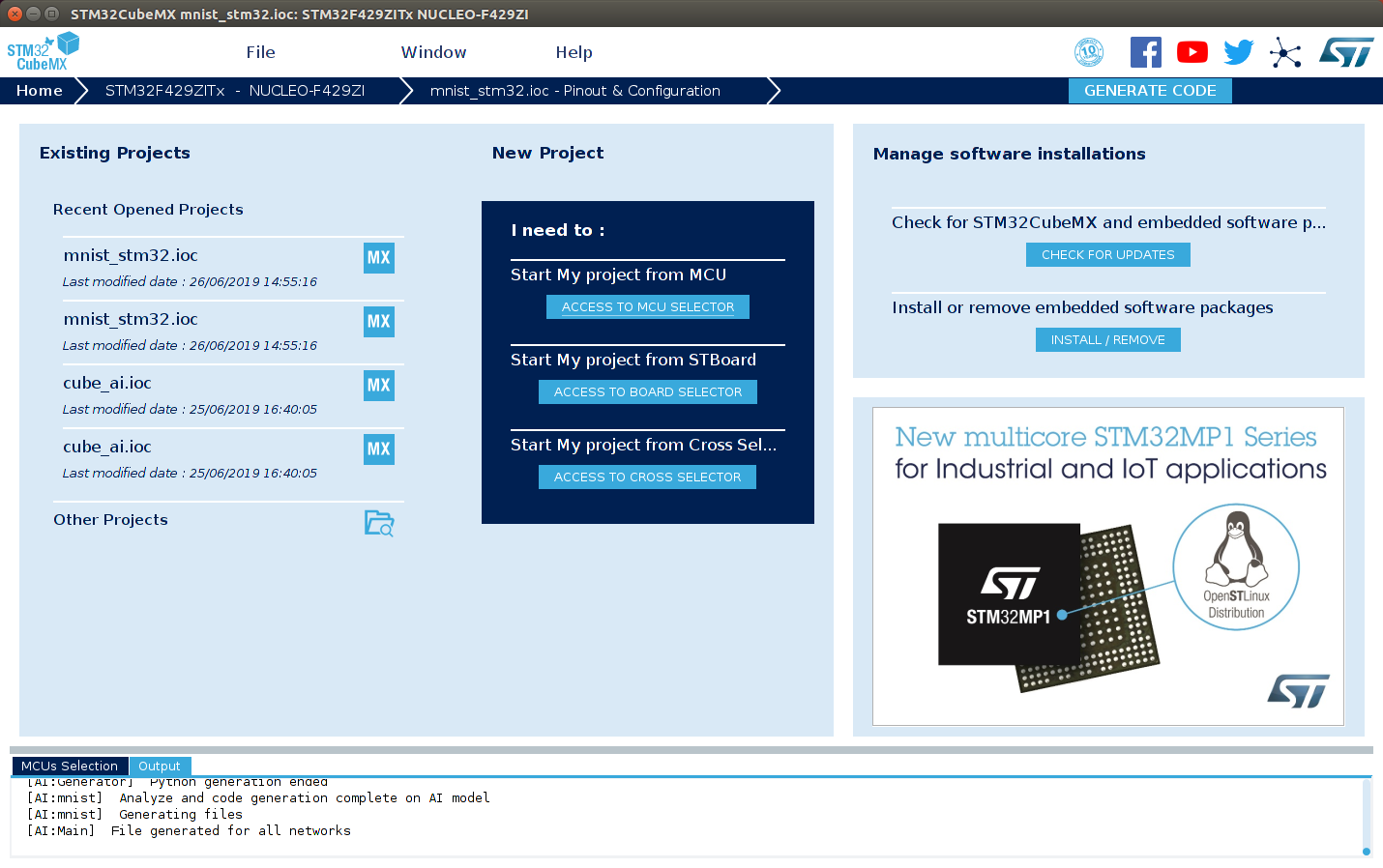
STM32CubeMX を実行すると、このような画面が表示されます。あ、一つ重要な注意が。X-CUBE-AI の Mac OS X 版は、どうも Mac OS のバージョンを選ぶようで、私の Mac(OS は 10.11.6。El Capitan)ではうまく動作しませんでした。バックグラウンドで実行する Python が正しく起動しないようです。そのため、今回は Linux 上で動くバージョンを利用しています。
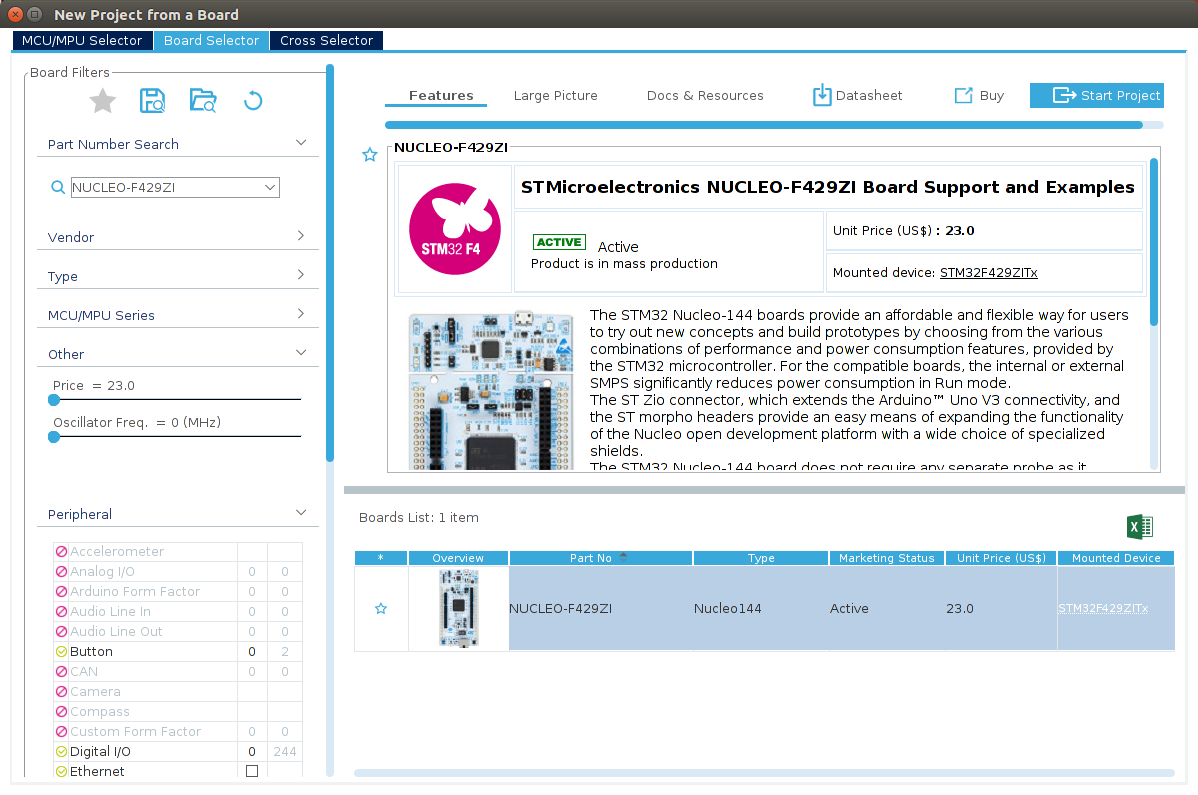
次に、Start My project from STBoard をクリックします。ウィンドウが開くので、左上の虫メガネアイコンのところにお持ちのボード(私の場合は Nucleo-144 STM32F429)名を入力し、右下のボードリストから正しいものを選び、Start Project ボタンを押します。
ペリフェラルをデフォルトモードに初期化するか聞いてくるので、Yes とします。こんな画面が表示されます。

次に、X-CUBE-AI パッケージを取り込みます。
画面上のほうの Additional Software をクリックすると次のようなウィンドウが表示されるので、X_CUBE_AI 3.4.0 版の、
- X-CUBE-AI Core
- X-CUBE-AI Application(SystemPerformance)
を選びます。SystemPerformance というのは、まずはマイコンボード上にニューラルネットモデルを展開し、ランダムなデータを入力テンソルとして与えながら、処理量(CPU サイクル数)を求める、というものです。まずはこれを試してみましょう。
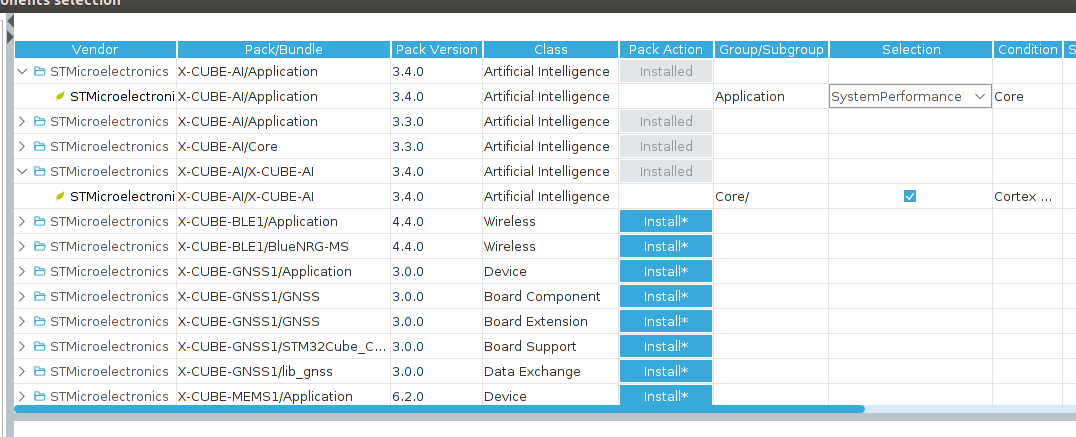
ウィンドウ下の Ok をクリックします。次のようなウィンドウが表示されるので、画面左下の Additional Software をプルダウンして STMicroelectronics.X-CUBE-AI…. という部分をクリックします。続いて、画面中央上に Mode というペインが開きますので、
- Artificial Intelligence X-CUBE-AI
- Artificial Intelligence Application
の 2つにチェックボックスを入れます。(下のウィンドウはそこまで進めたところです。)
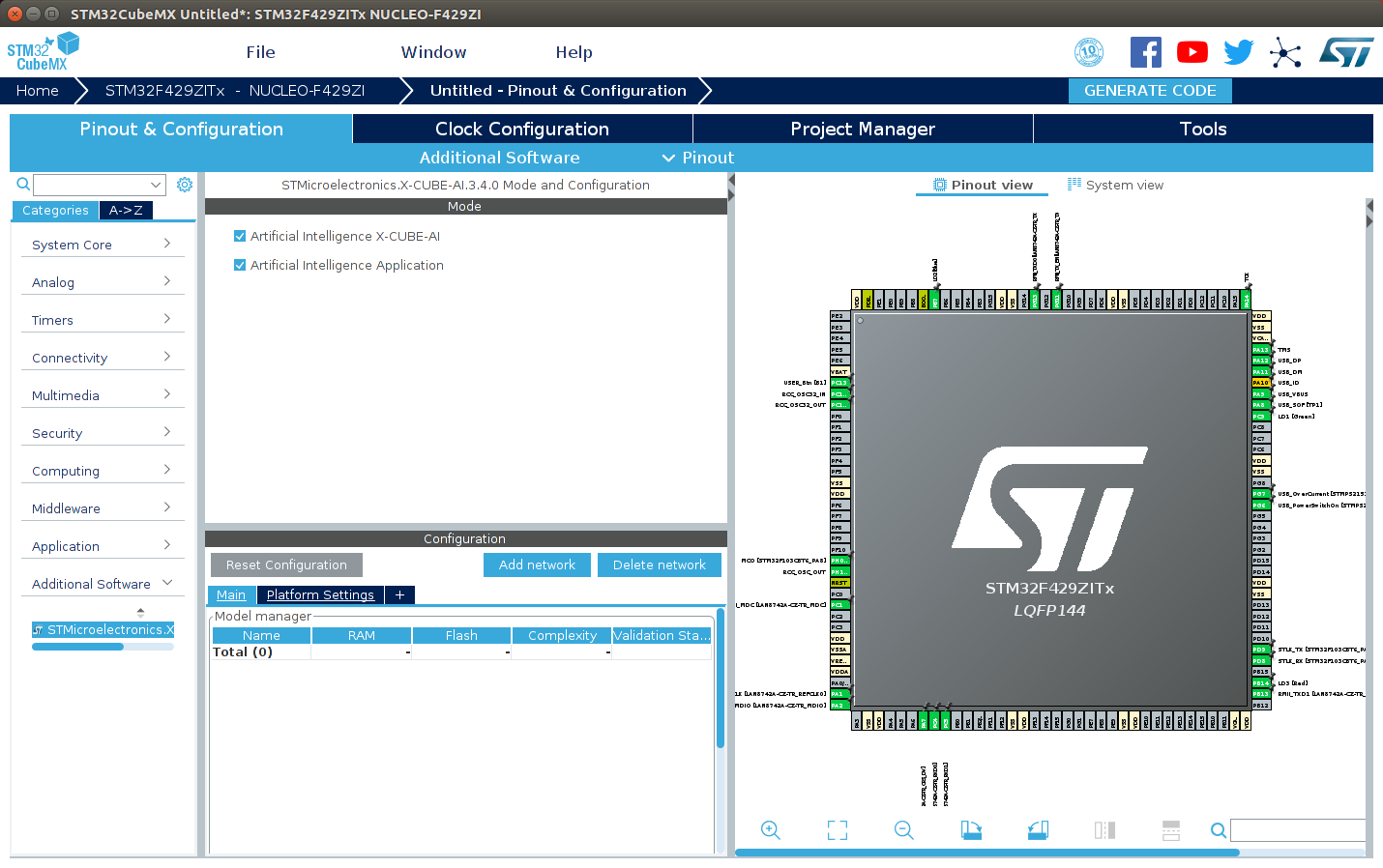
ここでようやくモデルを取り込めます。Configuration というペインで Add network をクリックすると、次のような画面に変わります。
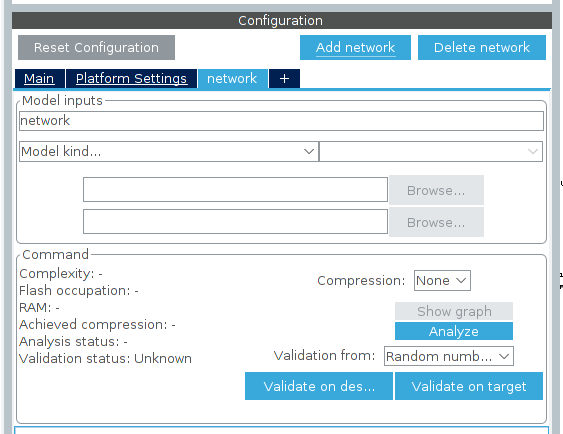
まず最初に、トップウィンドウのメニュー Window → Outputs にチェックを入れておきましょう。
Model inputs の名前が network となっているので、とりあえずこれを mnist に変更します。そして、Model kind… では Keras を選びます。Model and Topology では Saved model を選びます。Model というフィールドが表示されるので、その右の Browse をクリックし、先ほど生成したモデルファイル mnist_digits.h5 を選択します。そして、Analyze ボタンを押します。
Analyze ボタンの左にグリーンのチェックマークが付いたら OK です。ちなみに、今回は圧縮(Compression)をしませんが、Flash occupation の表示が大きく、マイコンのフラッシュ ROM に収まらない場合は圧縮を選んでみてください。4 と 8 というオプションがあり、数値が大きいほど圧縮率が高いのですが、オリジナルモデルとの差異が大きくなり、推論精度が下がります。
次に、Validation on desktop というボタンを押して validation を実行します。Validation status が Success になれば OK です。Compression レベルを上げると、validation が Failure になることがあります。つまり、パラメタの圧縮により、オリジナルモデルと圧縮モデルの間に差異が出て、推論精度が下がってしまっているという警告です。
ちなみに、Compression で validation エラーになっても、C 言語プロジェクトファイルの生成は可能です。ただし、ユーザーの責任で推論精度のチェックが必要になります。(デフォルトでは、オリジナルモデルに対して 1% 以上の誤差がある場合は validation エラーとなるようです。)
今回は非圧縮でプロジェクトを生成しますが、私の試みた感じでは、圧縮度 8 では validation エラーになるものの、ある程度の推論精度は得られているようです。(10個のテストサンプルを入力したところ、全て正解になった。)
マイコンプロジェクト(C言語)の作成
続いて、マイコン用にビルド(コンパイル)できるプロジェクトおよびソースコードを生成します。なお、どうもまだツールが枯れていないらしく、ときどき誤ったプロジェクトが生成されビルドエラーになることがあるようです。その場合は、CubeMX の .ioc ファイルだけ残して他を削除し、改めてプロジェクトを生成し直してみてください。
STM32CubeMX ではいろいろな IDE(統合開発ツール)が選べますが、今回は ac6 System Workbench for MCU(SW4STM32)というものを使うことにします。無償で Eclipse ベースの IDE であり、Windows, Mac OS X, Linux 上で動作します。
一つ、小さな設定が残っています。SystemPerformance テストや、後述の Validate on target では、マイコンボードが UART(シリアルポート)で通信できる必要があるので、その機能を有効にします。画面の Confiugration ペインの中で Platform Settings タブをクリックします。COM Port という表示の隣で、それぞれ USART: Asynchronous、USART3 を選びます。(なお、マイコンボードに依っては異なる設定となるかも知れません。)
次に、画面右上の GENERATE CODE ボタンをクリックします。次のような画面が表示されます。
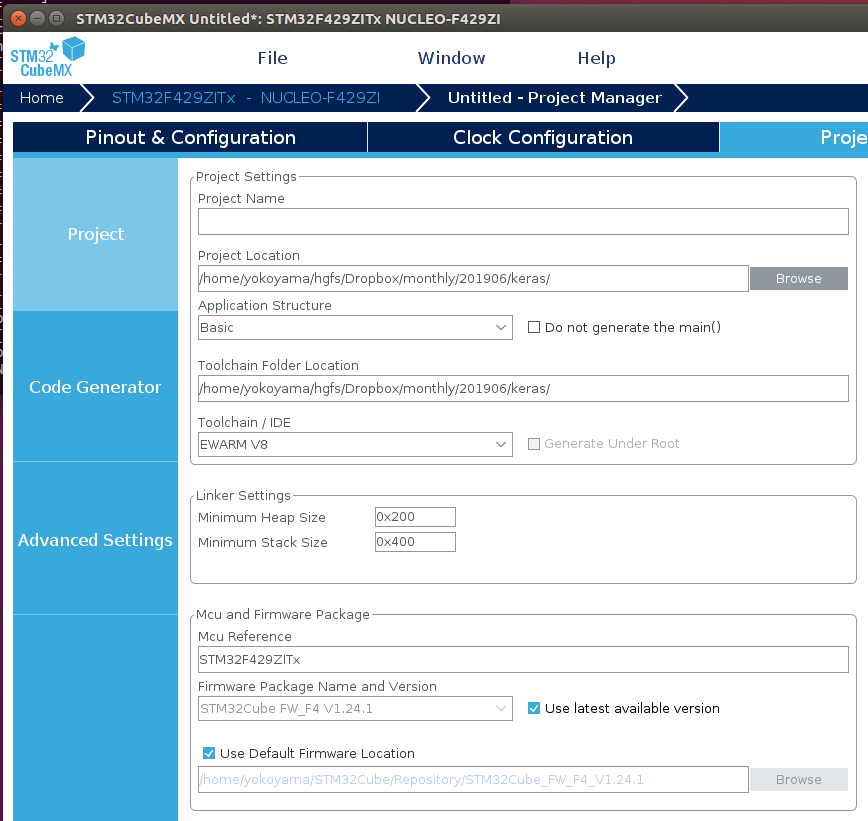
Project Name には、例えば mnist_stm32 などと付けます。Project Location は、その mnist_stm32 プロジェクトが置かれる Eclipse ワークスペースの場所です。この 2つを設定したら、次に以下を変更します。
- Toolchain / IDE → SW4STM32(上述の通り)
- Minimum Heap Size → 0x2000
- Minimum Stack Size → 0x4000
あとはそのままで OK です。再度 GENERATE CODE ボタンを押します。
生成できたら、忘れずに File → Save Project で .ioc ファイルを保存しておいてください。このファイルを STM32CubeMX でロードすれば、上記の設定を全て変更することができます。変更したら、再度 GENERATE CODE します。
ビルドしてマイコン上で実行してみる
パソコン上で System Workbench を起動します。ここからは Mac OS でも大丈夫です。
起動後、ワークスペースに上記のワークスペース(上の画面例では …/201906/keras)を開き、プロジェクト mnist_stm32 を import します。具体的には、File メニュー → Import … でダイアログを開き、General → Existing Projects into Workspace を選んで Next > ボタンをクリックします。
Select root directory でワークスペースディレクトリを選び、次のようなダイアログとなったら、mnist_stm32 を選んで Finish ボタンを押してください。(私の例では表示が少し異なり mnist_test となってますが、皆さんは上記で生成したプロジェクト名を選択してください。)
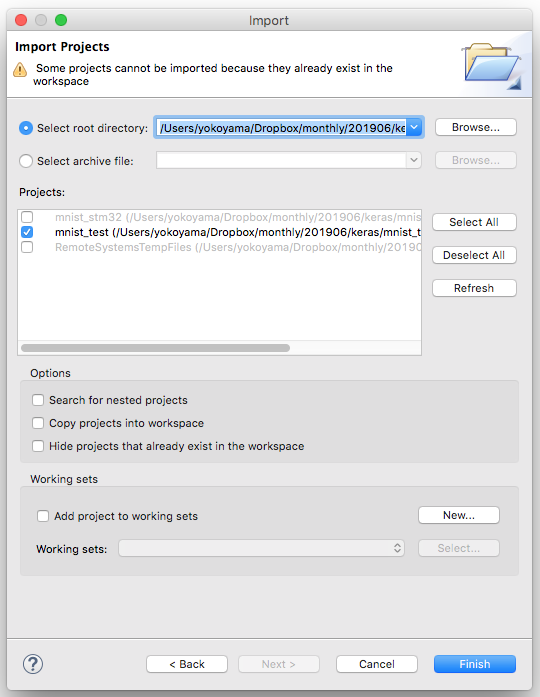
続いて、Project Explorer にて mnist_stm32 を右クリックで選び Build Project します。無事にビルドできたでしょうか。
次に、マイコンボードを USB ケーブルで PC に接続します。そうしたら、再度プロジェクト名を右クリックで選び、Debug As → AC6 STM32… を選びます。
ここでシリアルターミナルを開いておきましょう。Windows であれば Tera Term など。Mac OS であれば、私は screen コマンドを使います。例えば、コマンドラインで
screen /dev/tty.usbmodem144423 115200
のようにします。(usbmodem の後ろに数字は環境によって異なると思います。)
最後に、メニューから Run → Resume を選ぶと、マイコン上でプログラムが動作開始します。
プロジェクトのビルドで失敗する場合や、プログラムを実行しても正しく動作しない場合は、上述のように .ioc ファイルを残して全て削除し、再度やり直してみてください。まだツールが枯れていない可能性があります。
うまく動作すると、シリアルターミナルに次のような表示が出ます。
# # AI system performance measurement 2.1 # Compiled with GCC 7.2.1 STM32 Runtime configuration... Device : DevID:0x00000419 (UNKNOWN) RevID:0x00002001 Core Arch. : M4 - FPU PRESENT and used HAL version : 0x01070600 system clock : 168 MHz FLASH conf. : ACR=0x00000705 - Prefetch=True $I/$D=(True,True) latency=5 AI Network (AI platform API 1.0.0)... Found network "mnist" Creating the network "mnist".. Network configuration... Model name : mnist Model signature : 828fd8da7079c08f47fee3b04664a2ef Model datetime : Wed Jun 26 16:40:15 2019 Compile datetime : Jun 26 2019 16:47:59 Runtime revision : (3.3.0) Tool revision : (rev-) (3.3.0) Network info... signature : 0x0 nodes : 4 complexity : 101910 MACC activation : 3652 bytes weights : 407080 bytes inputs/outputs : 1/1 IN tensor format : HWC layout:28,1,28 (s:784 f:AI_BUFFER_FORMAT_FLOAT) OUT tensor format : HWC layout:1,1,10 (s:10 f:AI_BUFFER_FORMAT_FLOAT) Initializing the network Running PerfTest on "mnist" with random inputs (16 iterations)... ................ Results for "mnist", 16 inferences @168MHz/168MHz (complexity: 101910 MACC) duration : 6.357 ms (average) CPU cycles : 1068094 -214/+195 (average,-/+) CPU Workload : 0% cycles/MACC : 10.48 (average for all layers) used stack : 248 bytes used heap : 0:0 0:0 (req:allocated,req:released) cfg=0 Running PerfTest on "mnist" with random inputs (16 iterations)... ................
プロセッサの種類によって結果は異なると思いますが、上記の例ですと、一回の推論(手書き文字の判定)に 6.5ミリ秒程度を要していることが分かります。十分に高速ではないでしょうか!?
アプリケーションの書き方(例)
本当はここで、validation on target を説明しようと思ったのですが、ちょっと長くなりすぎますので、それは正式なマニュアル(UM2526: Getting started with X-CUBE-AI Expansion Package for Artificial Intelligence (AI) User Manual)に譲り、ここでは実際のアプリケーションプログラムの書き方(例)を御紹介したいと思います。
先ほど、Additional Software として X-CUBE-AI/Application(SystemPerformance)を選びましたが、実際にアプリケーションプログラムを作成したい場合は、SystemPerformance ではなくて ApplicationTemplate を選びます。そして、GENERATE CODE します。
しかしここでテンプレートはお世辞にも分かりやすいものではなく(と上記マニュアルにも書かれています)、SystemPerformace のコードを参考にしないとコードを書くのは困難です。皆様もいずれ、このコードを読むことになると思いますが、私と同様にセッカチな読者のために、コード例を示したいと思います。
ちなみに、繰り返しになりますが、本ツール(X-CUBE-AI)はまだまだ開発途上のようで、IDE(System Workbench など)や Eclipse に詳しくないと、ドツボにはまる可能性が高いです。その場合は、使用する IDE や Eclipse に詳しい方を探してみてください。もちろん、ファームロジックスにお問い合わせ頂ければ嬉しいです。 🙂
Src/app_x-cube-ai.c の修正
このファイルの中に MX_X_CUBE_AI_Process() という関数があり、その中からユーザーアプリケーションを呼び出すことを想定しています。この中に直接コードを書いても良いですし、皆さんの設計した関数を呼び出しても良いでしょう。以下では、ここに書く内容(あるいは呼び出し先関数の内容)を示します。
あまり綺麗なコードではありませんが、御容赦ください。
#include <stdio.h>
#include <bsp_ai.h>
static const int N_SAMPLES = 10; // サンプル入力の数
static const int WIDTH = 28;
static const int HEIGHT = 28;
/*
* ここ vect.h ではサンプル入力ベクタを取り込んでいます。
* こんな感じです。
* static const uint8_t vect[10][28][28] = {
* ...
* };
* 一番外側がサンプル入力ベクタの数、続いて Y (height 方向)、X (width 方向) です。
* NumPy とか使って、うまく書き出してください。(うまいツールないのかな?)
*/
#include "vect.h"
/*
* この辺は、ST 社のサンプルコードから引用です。
*/
#define AI_BUFFER_NULL(ptr_) \
AI_BUFFER_OBJ_INIT( \
AI_BUFFER_FORMAT_NONE|AI_BUFFER_FMT_FLAG_CONST, \
0, 0, 0, 0, \
AI_HANDLE_PTR(ptr_))
/* これもそうです */
AI_ALIGNED(4)
static ai_u8 activations[AI_MNIST_DATA_ACTIVATIONS_SIZE];
static ai_float input_tensor[AI_MNIST_IN_1_SIZE];
static ai_float output_tensor[AI_MNIST_OUT_1_SIZE];
ai_handle handle;
ai_network_report report;
ai_buffer ai_input;
ai_buffer ai_output;
void user_main(void)
{
/* この辺もそう */
/* build params structure to provide the reference of the
* activation and weight buffers */
const ai_network_params params = {
AI_BUFFER_NULL(NULL),
AI_BUFFER_NULL(activations) };
int i;
int j;
int x;
int y;
int nn_max;
ai_error err;
ai_i32 batch;
ai_float max;
/* ニューラルネットを生成します */
err = ai_mnetwork_create("mnist", &handle, NULL);
if (err.type) {
printf("ai_mnetwork_create() failed.\r\n");
for (;;)
/* エラーなら無限ループ。以下同様 */;
}
/* ニューラルネットの素性を読み出します */
if (ai_mnetwork_get_info(handle, &report) == false) {
printf("ai_mnetwork_get_info() failed.\r\n");
for (;;)
;
}
/* ニューラルネットを初期化します */
if (ai_mnetwork_init(handle, ¶ms) == false) {
printf("ai_mnetwork_init() failed.\r\n");
for (;;)
;
}
/* 入力と出力テンソルの設定をします */
ai_input = report.inputs;
ai_output = report.outputs;
ai_input.n_batches = 1;
ai_input.data = AI_HANDLE_PTR(input_tensor);
ai_output.n_batches = 1;
ai_output.data = AI_HANDLE_PTR(output_tensor);
/* 実際に推論させ、結果を調べるループです */
for (i = 0; i < N_SAMPLES; i ++) {
for (y = 0; y < HEIGHT; y ++)
for (x = 0; x < WIDTH; x ++) {
/* 入力テンソルの配列にテストベクタをコピーします */
input_tensor[y * WIDTH + x] =
((ai_float) vect[i][y][x]) / 255.0; // 値の正規化
}
/* 推論を走らせます */
batch = ai_mnetwork_run(handle, &ai_input, &ai_output);
if (batch != 1) {
printf("ai_mnetwork_run() failed.\r\n");
for (;;)
;
}
/*
* softmax の出力 10個から、一番正しそうなやつを選びます。
* 最大値サーチですね。もっとカッコ良く書いても可です。
*/
max = -1.0;
nn_max = -1;
for (j = 0; j < 10; j ++) {
if (output_tensor[j] > max) {
max = output_tensor[j];
nn_max = j;
}
}
printf("sample #%d: prediction = %d\r\n", i, nn_max);
}
/* 終わったら無限ループ */
for (;;)
;
}
/*
* これがないと printf() できないので、
* これを入れておきます。
* ネットで探すといろいろあります。
* 特に理解してなくて良いです。
*/
int __io_putchar(int ch)
{
extern UART_HandleTypeDef huart3;
HAL_UART_Transmit(&huart3, (uint8_t *)&ch, 1, 0xFFFF);
return ch;
}
結果はこんな感じです。
sample #0: prediction = 7 sample #1: prediction = 2 sample #2: prediction = 1 sample #3: prediction = 0 sample #4: prediction = 4 sample #5: prediction = 1 sample #6: prediction = 4 sample #7: prediction = 9 sample #8: prediction = 5 sample #9: prediction = 9
Keras で読み出したテストセットのラベルを見てみましょう。(以下 Python のコード)
> test_labels[0:10] array([7, 2, 1, 0, 4, 1, 4, 9, 5, 9], dtype=uint8)
とりあえず、10個正解です!
いかがでしょうか。皆さんも、マイコン上で動作するニューラルネットを書けそうな気がしてきましたでしょうか!?
今日はここまで。STM32 マイコンでニューラルネットを試してみたい方の御参考になれば幸いです。